BM25: wyszukiwanie po słowach kluczowych
Ulepsz wyszukiwanie w swojej aplikacji! Wdróż BM25: odkryj jak działa, poznaj problemy i praktyczne porady 🚀

Co to BM25?
BM25 to funkcja, która punktuje dopasowanie dokumentów do zapytania użytkownika. Jeśli słowa w zapytaniu znajdują się w dokumencie, to dokument otrzyma punkty.
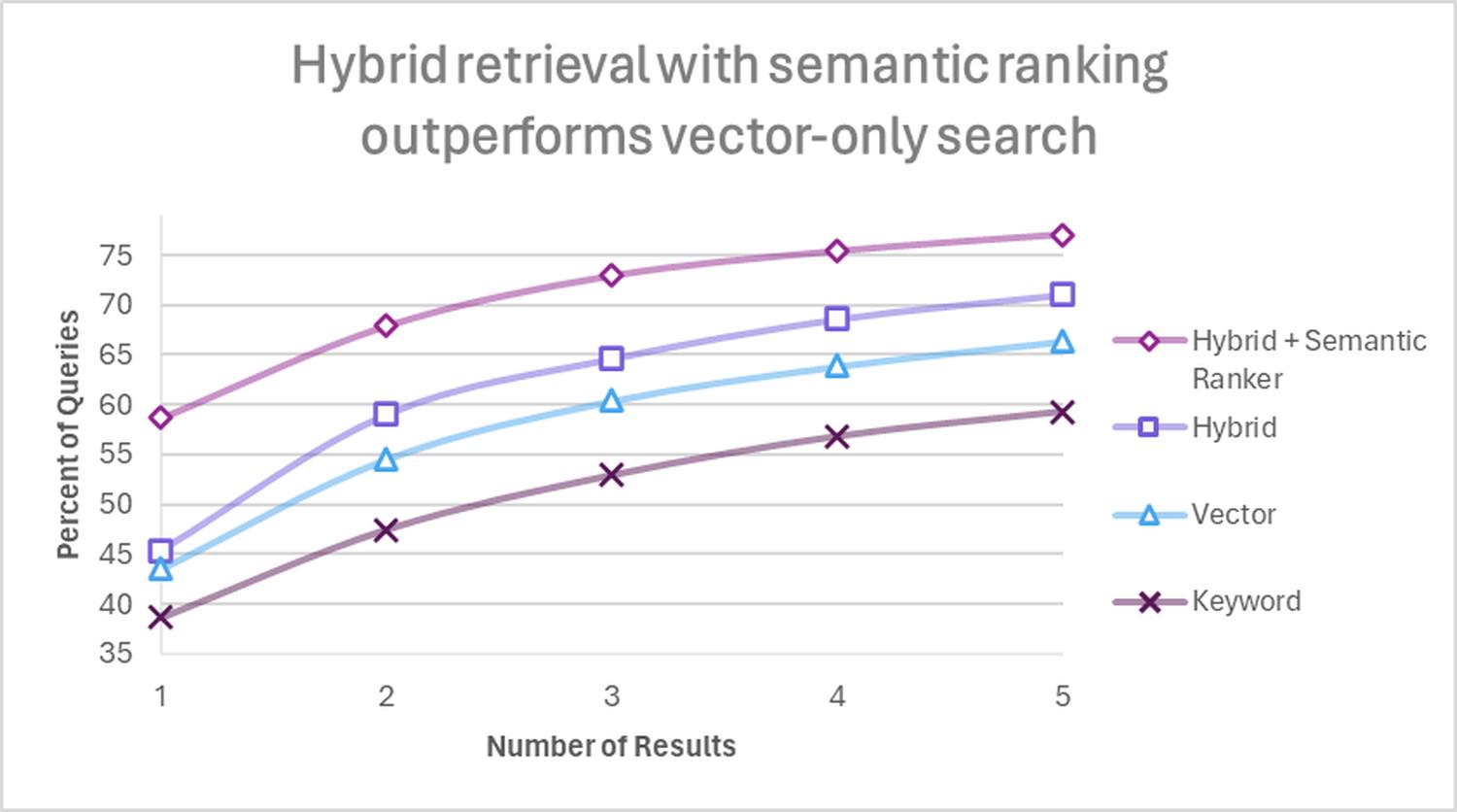
BM25 przyda się wszędzie tam, gdzie potrzebujemy wyszukiwanie po słowach kluczowych. Jest wykorzystywane jako domyślny algorytm ElasticSearch czy w aplikacjach RAG do wyszukiwania hybrydowego w połączeniu z embeddingami.
Zrozumienie mechanizmu działania oraz sztuczek związanych z implementacją jest niezwykle przydatne - w szczególności dla języka polskiego!
Jak działa BM25?
Algorytm analizuje częstość występowania poszczególnych słów kluczowych w zbiorze dokumentów.
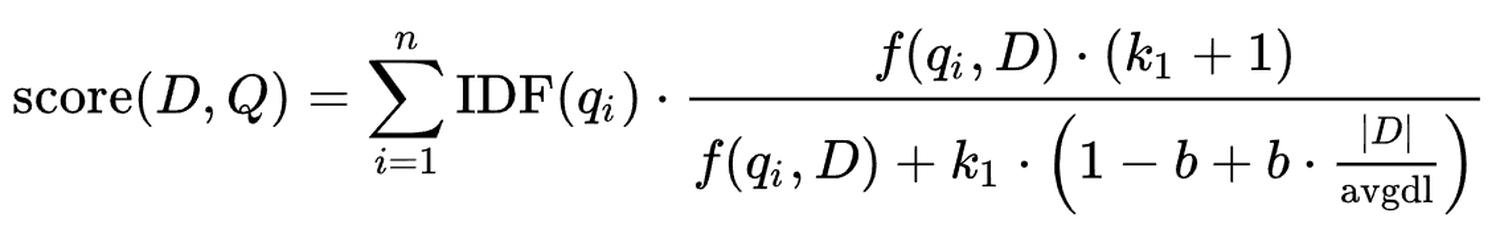
Wzór może być przytłaczający ;) Wytłumaczę co z niego wynika, a zainteresowanych formalną postacią odsyłam do Wikipedii oraz świetnego artykułu porównującego TF/IDF i BM25.
Najważniejsze zasady działania
Dokumenty oraz zapytania w pierwszej kolejności dzielone są na termy: przyjmijmy, że 1 słowo to 1 term. [1]
Im rzadziej dopasowane słowa występują w dokumentach, tym bardziej będą punktowane:
- Jeśli np. przeszukujemy zasoby księgarni, to dla zapytania “książka eklektyzm”, dopasowania do rzadziej występującego słowa “eklektyzm” będą bardziej punktowane niż do słowa “książka”.
- Pospolite słowa będą znacznie mniej punktowane: np. w zdaniu “co na obiad”, dopasowanie do “co wrzucić na grilla” będzie znacznie słabsze niż “pomysły na obiad”
Im słowo częściej będzie występowało w dokumencie, tym dokument otrzyma większą liczbę punktów. Dzięki temu, dla zapytania “kot” będzie bardziej punktowany artykuł o kotach, niż encyklopedia wymieniajaca wszystkie zwierzęta:
- artykuł wymieni “kot” 20 razy, mając 2 strony tekstu
- encyklopedia wymieni “kot” 30 razy, ale na 100 stron tekstu
BM25 ignoruje również względną pozycję słów w dokumencie. Dla zdania:
- “gdzie jest czerwony słoń?”
Poniższe zdania będą miały identyczne dopasowania:
- “czerwony notatnik, czarny słoń”
- “czerwony słoń, czarny notatnik”
Każde słowo jest rozpatrywane indywidualnie.
Info
[1] Dokumenty de facto są dzielone na termy - przeważnie to są słowa, ale równie dobrze możemy wykorzystać inny podział.
- Możemy dzielić dokumenty na
n-gramy, które grupują słowa razem:
bi-gramyto połączenia dwóch słówtri-gramyto połączenia trzech słów
To rozwiązuje problem wcześniej wymienionego czerwonego słonia!
- Możemy dzielić dokumenty na tokeny z wykorzystaniem np. tokenizera
tiktoken
To zmniejsza konieczność wykorzystywania stemmingu / lematyzacji (o tym za chwilę).
Oba podejścia mają swoje trade-offy, więc zainteresowanych odsyłam do Google i eksperymentów ;)
Pre-processing: klucz do dobrych wyników
BM25 dla skutecznego działania wymaga pre-processingu danych wejściowych. Przedstawię na przykładach istotne kroki:
Lowercasing
BM25 domyślnie jest case-sensitive: rozróżnia pomiędzy dużymi a małymi znakami. Token “Czerwony” nie będzie powiązany z tokenem “czerwony”.
Czy to jest pożądane w Twojej aplikacji? Jeśli nie, to zamiana tekstu na małe znaki (lowercasing) wyeliminuje ten problem. Jednak jeśli np. przetwarzasz kody seryjne, które rozróżniają małe i duże znaki, i chciałbyś umożliwić ich precyzyjne wyszukiwanie, to wprowadzenie lowercasingu może pogorszyć wyniki!
Stąd zawsze warto się zastanowić: czy chcemy wprowadzić pre-processing?
# Przed zmianami
documents = ["Słońce jest zielone"]
query = "Jakiego koloru jest słońce"
search_bm25(documents, query) == []
# Brak dokumentów - Słońce vs słońce
# Po zmianach
documents = ["słońce jest zielone"]
query = "jakiego koloru jest słońce"
search_bm25(documents, query) == ["słońce jest zielone"]
# Match na słowie słońce
Uwaga
Zauważ, że dane wejściowe muszą być przetworzone w identyczny sposób, co dane dokumentów w indeksie. Jeśli np. chcemy usunąć polskie znaki - to musimy to robić zarówno dla zapytania użytkownika, jak i dokumentów. To tyczy się każdego kroku.
Usuwanie stopwordów
Info
Stopwordy to słowa powszechnie występujące w danym języku, na przykład: “to”, “w”, “jak”, “z”, “na”.
Usuwanie stopwordów sprawia, że najczęściej występujące słowa w danym języku zostaną usunięte:
remove_stopwords("jaka jest pogoda dzisiaj?") == "pogoda dzisiaj?"
remove_stopwords("pies jest bardzo szczęśliwy") == "pies szczęśliwy"
Po usunięciu stopwordów, zdanie “jaka jest pogoda dzisiaj?” nie zostanie dopasowane do zdania “pies jest bardzo szczęśliwy” - usunęliśmy wspólny mianownik “jest”.
Nie istnieje uniwersalna lista stopwordów - podlinkuję przykładową listę dla języka polskiego.
Problematyka
Usuwanie stopwordów ma swoje problemy:
- Stopwordy różnią się w zależności od języka. Gdybyśmy wykorzystali angielską listę stopwordów w polskim zapytaniu do wyszukiwarki, to nie moglibyśmy znaleźć informacji o mostach - bowiem “most” to angielski stopword! Oznacza to, że jeśli tworzymy indeks BM25 operujący na kilku językach, to musimy poprawnie zidentyfikować język przed doborem odpowiedniej listy. Analogicznie z zapytaniami użytkownika.
- Stopwordy mogą mieć znaczenie semantyczne w zdaniu - mówiąc o “The Rock”, chodzi nam o amerykańskiego aktora; mówiąc o “rock”, chodzi nam o kamienie.
Ponadto: usuwanie stopwordów nie jest konieczne przy BM25. Algorytm wyżej punktuje unikalne słowa, więc przy dostatecznie dużej liczbie dokumentów, powszechnie występujące stopwordy będą punktowane w niewielkim stopniu. Niewłaściwe dopasowania będą miały niską punktację.
Jak ze wszystkimi krokami: wprowadź takie przetwarzanie dla swojego datasetu i przetestuj jak wpłynęło na wyniki :)
Stemming i lematyzacja
Kluczowy problem - dla BM25, “pies”, “psy” oraz “psach” to 3 różne słowa! Rozpatrzmy następujące zdania:
- “kleszcz na psie”
- “poradnik: zwalczanie kleszczy u Twojego psa”
Zdania nie zostaną dopasowane - “kleszcz” to nie “kleszczy”, a “psie” to nie “psa”.
Dwie metody, które mogą rozwiązać ten problem, to stemming i lematyzacja.
Stemming polega na wydobyciu ze słowa rdzenia, czyli obcięcie końcówki fleksyjnej. Wynikiem niekoniecznie jest poprawne słowo, ale umożliwia to porównywanie zbliżonych słów:
stemmer('teraz') == 'teraz'
stemmer('przeszywająco') == 'przeszywa'
stemmer('krzyczała') == 'krzy'
stemmer('kobiety') == 'kobiet'
stemmer('kobietom') == 'kobiet'
stemmer('kobieta') == 'kobiet'
Lematyzacja polega na wydobyciu formy podstawowej, czyli np. bezokolicznika dla czasowników czy liczby pojedynczej rzeczownika:
lemmatization('teraz') == 'teraz'
lemmatization('przeszywająco') == 'przeszywać'
lemmatization('krzyczała') == 'krzyczeć'
lemmatization('kobiety') == 'kobieta'
Lematyzacja jest bardziej zasobożerna od stemmingu, jednak przeważnie osiąga lepsze wyniki. Dla języka polskiego możemy zastosować m.in. PoLemma do lematyzacji oraz Stempel do stemmingu.
Wracając do przykładu - po zastosowaniu lematyzacji, nasz algorytm BM25 będzie w stanie dopasować zdania:
- “kleszcz na psie” > “kleszcz na pies”
- “poradnik: zwalczanie kleszczy u Twojego psa” > “poradnik: zwalczyć kleszcz u twój pies”
Usuwanie polskich znaków
W pre-processingu możemy także usuwać polskie znaki, co wyeliminuje niedopasowania pomiędzy “zażółć gęślą jaźń” a “zazolc gesla jazn”. Jednak - jeśli dodamy ten krok przetwarzania, to słowo “łoś” zacznie być powiązane z loteryjnym “los”. Coś za coś!

Literówki i synonimy
BM25 nie powiąże słowa “pies” z słowem “peis”; nie powiąże również słowa “auto” ze słowem “samochód”. Na moment pisania artykułu nie znam rozwiązania, ale zakreślam problem ;)
Implementacja BM25
Na przykładzie Pythona - możesz zastosować jedną z gotowych bibliotek, w szczególności:
- rank-bm25 jest najbardziej popularną biblioteką, ale nie jest najlepsza;
- znacznie lepszym wyborem będzie bm25s, która jest kilkaset razy szybsza od
rank-bm25i wspiera m.in. zapisywanie indeksu w memory-mapped plikach
Równie dobrą opcją jest indeks w bazie danych - osobiście polecam ParadeDB, które jest Postgresem z doinstalowanym rozszerzeniem pg_search, które umożliwia indeksowanie BM25 na kolumnie tekstowej. Rozszerzenie również umożliwia bardziej skomplikowane zapytania. Projekt jest objęty licencją AGPL v3.0.
Inne znane mi bazy danych z wsparciem dla BM25, których jednak nie testowałem, to ElasticSearch oraz Weaviate.
Wskazówka
Jeśli wybrana przez Ciebie baza/biblioteka nie wspiera odpowiedniego pre-processingu, zaimplementuj przetwarzanie po stronie aplikacji i przekazuj do indeksu BM25 już przetworzone dokumenty.
Pamiętaj o benchmarkach
Pamiętaj, aby przed rozpoczęciem pracy stworzyć benchmark trafności Twojej wyszukiwarki, z wybranymi metrykami, np. recall@3 / recall@5. To umożliwi Ci ustalić, czy wprowadzone zmiany polepszają, czy pogarszają jakość Waszej aplikacji - nie wierz intuicji!
recall_a = test_recall_bm25_bez_preprocessingu(test_set)
# 85%
recall_b = test_recall_bm25_z_niestosownym_preprocessingiem(test_set)
# 67%
# Wniosek: wersja A > wersja B
Słowa końcowe i odnośniki
Mam nadzieję, że post okazał się pomocny :) Jeśli chcesz przeczytać więcej artykułów w tej tematyce, zostawiam Ci listę:
- Better Sparse Retrieval: Extending BM25 With Subwords, Evan Harris - artykuł przedstawiający ulepszenia do BM25, z konceptem wykorzystania tiktoken jako alternatywę do stemmingu;
- Understanding TF-IDF and BM-25, Rudi Seitz - świetne wytłumaczenie różnic między TF/IDF a BM25;
- Polish NLP Resources, Sławomir Dadas, lista zasobów NLP w języku polskim
- Stop Stopping - o usuwaniu stopwordów
- Czym jest NLP? - źródło przykładów dla stemming vs lematyzacja
- What Are Stemming and Lemmatization?, IBM - stemming vs lematyzacja
Jeśli dostrzegasz jakieś błędy, nieścisłości, lub chciał*byś po prostu porozmawiać o tej tematyce - zapraszam do kontaktu na LinkedInie lub e-mailowego - adres znajdziesz w stopce :)
Możesz śledzić mój blog za pomocą dowolnego
 czytnika RSS!
czytnika RSS!
Maciej Kaszkowiak
Piszę o rzeczach, które uważam za interesujące, m.in. o sztucznej inteligencji, projektach, programowaniu i podróżach - zobacz wszystkie posty.

EnsembleAI 2025, czyli 3 miejsce zdobyte atakiem rakietowym
Poznaj naszą relację z tegorocznego hackathonu EnsembleAI! Inaczej rakiety dolecą do Ciebie ;)

Query rewriting - doprecyzuj zapytania użytkowników
Czym jest query rewriting? Dlaczego przyda Ci się zawsze, gdy tworzysz chatbota? Jak to wdrożyć? Przeczytaj w artykule!

Wdrażanie testów w AI: fundament dobrej aplikacji
Jak mierzyć skuteczność aplikacji? Dlaczego? Na co uważać? - artykuł odpowie na te pytania i umożliwi Ci tworzenie lepszych aplikacji opartych o AI!