RAG, czyli jak rozmawiać z naszymi dokumentami?
Odkryj, jak Retrieval Augmented Generation umożliwia udzielanie trafnych odpowiedzi z wiedzy specjalistycznej przez duże modele językowe (LLM).

Co to Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) to technika wzmacniania wyników dużych modeli językowych z wykorzystaniem zewnętrznych źródeł danych.
Przykładem dużego modelu językowego (LLM) może być ChatGPT, LLaMA czy GPT-4.
Najprostszy przykład: wysyłamy do chatbota PDF, a następnie zadajemy pytania na temat treści dokumentu. To najprostsze zastosowanie RAG :)
Wykorzystywanie RAG w praktyce
Przyjmijmy, że chcemy zbudować chatbota, który udziela odpowiedzi na temat wiedzy specjalistycznej o niszowej dziedzinie.
Wiedza, którą chcemy udzielić, jest na tyle niedostępna, że ChatGPT nie potrafi odpowiadać na pytania użytkownika. Odpowiada, że nie wie lub zmyśla fakty.
Aby nasz chat-bot zadziałał, potrzebujemy sposobu, aby stał się mądrzejszy. Tutaj wchodzi w grę RAG:
- Budujemy naszą bazę wiedzy:
- Zbieramy np. 50 PDFów ze specjalistyczną wiedzą;
- Każdy PDF przetwarzamy, wyciągając z niego tekst;
Nasze dokumenty musimy podzielić na mniejsze części, ponieważ nie jesteśmy obecnie w stanie zasilić LLM tekstem wszystkich 50 PDFów. Ich rozmiar wykracza poza dopuszczalny zakres.
- Przetwarzamy wiedzę:
- Dokumenty dzielimy na części o wielkości paragrafów;
- Każdą część przetwarzamy do formatu odczytywalnego maszynowo;
- Przetworzone dane zapisujemy w bazie wektorowej;
Po jednorazowym stworzeniu bazy wiedzy, jesteśmy w stanie wykorzystać ją do odpowiedzi na pytania. Przyjmijmy, że użytkownik skierował pytanie do naszego chatbota “Jak zrobić skomplikowaną rzecz X?”:
- Przetwarzamy pytanie do formatu odczytywalnego maszynowo.
Format przetworzonej wiedzy i pytania jest identyczny. To są tak zwane embeddingi :)
- Szukamy dokumentu najbardziej pasującego do zadanego pytania.
Na przetworzonym tekście możemy wykonać prostą operację matematyczną, aby określić najbardziej zbliżony fragment.
Po znalezieniu najbardziej pasującego fragmentu, jesteśmy w stanie zapytać naszego modelu językowego:
Na podstawie podanego kontekstu, odpowiedz na pytanie użytkownika. Jeśli odpowiedź nie znajduje się w kontekście, odpowiedz “nie wiem”.
Kontekst: (nasz najbardziej pasujący dokument)
Pytanie: Jak zrobić skomplikowaną rzecz X?
LLM z kolei może odpowiedzieć:
Skomplikowaną rzecz X robi się poprzez (odpowiedź na podstawie informacji z dokumentów).
Lub przyznać się, że nie wie:
Nie mam dostępu do takich informacji.
Ot cała filozofia - to właśnie nazywa się Retrieval Augmented Generation :)
Diabeł tkwi w szczegółach
Powyższy przykład jest oczywiście uproszczony, w celu przedstawienia konceptu.
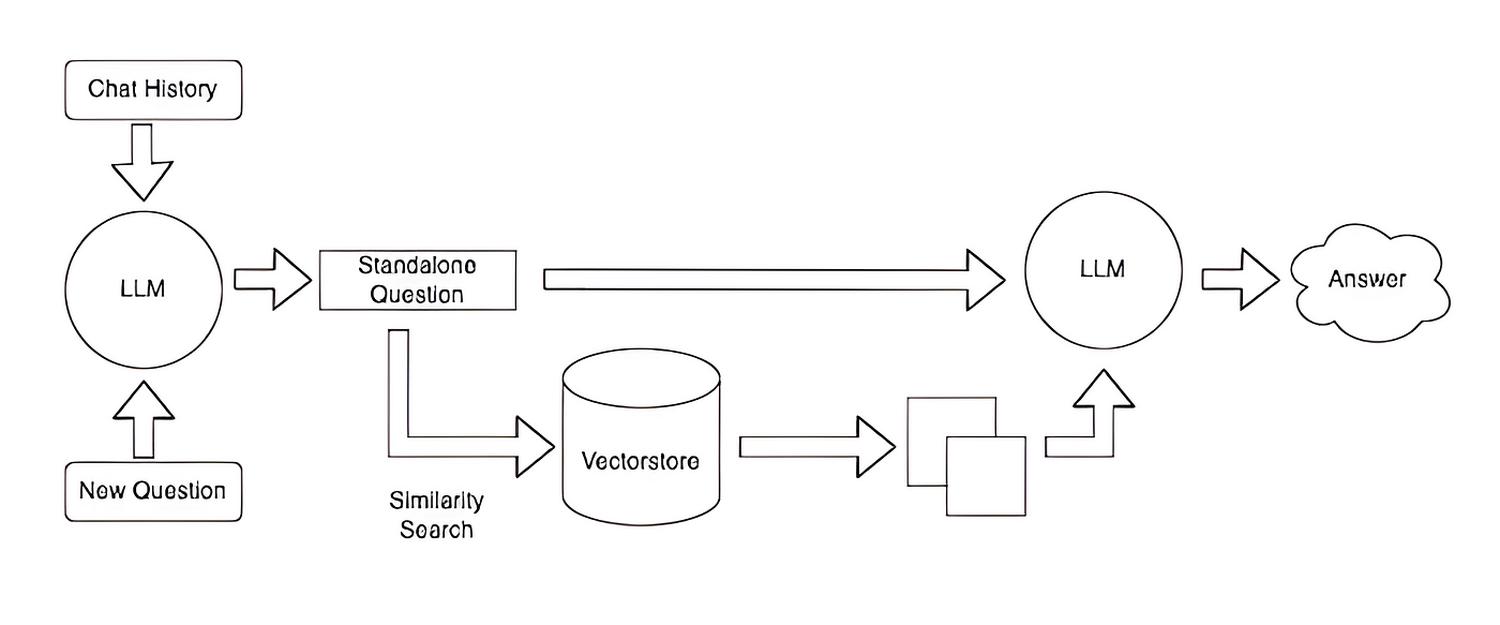
Szczegóły techniczne:
- Pytania do LLM, zwane jako “prompty”, piszemy w języku angielskim;
- Przetwarzanie tekstu nazywa się generowaniem embeddingów. Proces ten odbywa się z wykorzystaniem ML, chociażby modeli SBERT;
- Embeddingi zapisujemy przeważnie w bazie wektorowej;
- Embeddingi umożliwiają nam wyszukiwanie semantyczne, w odróżnieniu od tradycyjnego wyszukiwania leksykalnego;
- Proces porównywania wektorów można przyspieszyć kosztem jakości wyszukiwania;
- Fragmenty tekstu mogą się częściowo pokrywać, aby lepiej trafić w kontekst.
Każdy z powyższych punktów można bardzo szczegółowo opisać - tematyka jest bardzo szeroka oraz na dzień dzisiejszy szybko rozwijająca!
Bardzo serdecznie Was zachęcam do przeczytania mojego artykułu o embeddingach, który przedstawia jak wyszukiwanie dokumentów odbywa się od strony technicznej!
Możesz śledzić mój blog za pomocą dowolnego
 czytnika RSS!
czytnika RSS!
Maciej Kaszkowiak
Piszę o rzeczach, które uważam za interesujące, m.in. o sztucznej inteligencji, projektach, programowaniu i podróżach - zobacz wszystkie posty.

EnsembleAI 2025, czyli 3 miejsce zdobyte atakiem rakietowym
Poznaj naszą relację z tegorocznego hackathonu EnsembleAI! Inaczej rakiety dolecą do Ciebie ;)

Query rewriting - doprecyzuj zapytania użytkowników
Czym jest query rewriting? Dlaczego przyda Ci się zawsze, gdy tworzysz chatbota? Jak to wdrożyć? Przeczytaj w artykule!

BM25: wyszukiwanie po słowach kluczowych
Ulepsz wyszukiwanie w swojej aplikacji! Wdróż BM25: odkryj jak działa, poznaj problemy i praktyczne porady 🚀