Wdrażanie testów w AI: fundament dobrej aplikacji
Jak mierzyć skuteczność aplikacji? Dlaczego? Na co uważać? - artykuł odpowie na te pytania i umożliwi Ci tworzenie lepszych aplikacji opartych o AI!

Artykuł jest skierowany dla każdej osoby pracującej z AI. Jeśli dopiero zaczynasz, polecam wytłumaczenie co to LLM i RAG 🚀
Po co w ogóle mierzyć skuteczność?
Wyobraźmy sobie następującą sytuację:
Odpowiadasz razem z Twoim zespołem za rozwój najnowszej aplikacji AI: generator poematów o kotach.
Spokojny piątkowy poranek. Twój <klient / użytkownik / tester> zgłasza krytyczny błąd: aplikacja nagle napisała poemat o psie! Dostałeś zadanie, aby to naprawić, więc dostosowujesz mechanizm pod znaleziony przypadek. Ponownie testujesz załączone pytanie i… działa, więc wdrażasz poprawkę na produkcję :)
No właśnie - czy na pewno działa? Nie masz zestawu testów, więc:
- nie wiesz, że naprawa 1 przypadku spowodowała wygenerowanie błędnej odpowiedzi w 10 innych przypadkach;
- po zmianach Twoja aplikacja czasami zaczęła generować poematy po chińsku - nie wiesz dlaczego, ale musisz przygotować kolejną łatkę;
- wcześniej zgłoszony błąd, który naprawiłeś miesiąc temu, nagle zaczął ponownie występować w systemie;
- nie jesteś w stanie stwierdzić, czy Twoja aplikacja się w ogóle poprawia - w końcu cały czas pojawiają się nowe błędy! Jak udowodnisz, że zmiany faktycznie rozwijają aplikację?
I tutaj wchodzą testy, które rozwiążą Twoje problemy! Nie tylko generując poematy o kotach, ale w szczególności w realnych aplikacjach: chatbotach, systemach agentowych, narzędziach do przetwarzania dokumentów, etc.
Testy w aplikacjach AI są konieczne
Wprowadzenie testów pomoże Wam ustalić, że zmiana X polepszyła skuteczność aplikacji z 80% do 85%, a kolejna zmiana Y pogorszyła skuteczność z 85% do 73%. Dzięki temu:
- będziesz w stanie jasno ustalić, czy skuteczność aplikacji się polepsza, lub czy np. ma słabe punkty;
- zapobiegniesz nieświadomego wprowadzenia regresji, czyli pogorszenia jakości odpowiedzi lub zwiększenia częstotliwości błędów;
- ponadto: tworząc testy, bardzo szybko wyklarują się wymagania Twojej aplikacji oraz co powinno być Twoim priorytetem
Uważam, że w aplikacjach opartych o AI testy to konieczność! Nie możesz ich całkowicie pominąć, np. poprzez próbę zminimalizowania kosztów. To tylko zadziała, jeśli Twoja aplikacja nie musi być dobra, lub przewidujesz, że nie trafi nigdzie na produkcję - wtedy droga wolna ;)
Mój CRUD jest w 100% poprawny i nie ma żadnych błędów. Dlaczego tak nie mogę zrobić z AI?
Tradycyjne aplikacje (bez AI) opierają się o logikę, którą zawsze jesteśmy w stanie dostosować pod nasze wymagania biznesowe. Jeśli nie mamy błędów w implementacji, nasza aplikacja zawsze będzie robiła dokładnie to, czego od niej oczekujemy.
Nie możemy zagwarantować takiej 100% skuteczności w aplikacjach opartych o AI. Gdy nasza aplikacja odpowiada poprawnie na 99% zapytań użytkowników, to nadal jesteśmy w stanie znaleźć brakujący odsetek 1%, w którym pojawiły się błędy. A testy manualne wykażą jedynie ten 1% błędów - bez zwrócenia uwagi na skalę problemu :)
Wskazówka
Dlaczego nie możemy zagwarantować 100% skuteczności?
Pod spodem modelu językowego, jak np. ChatGPT, nie mamy serii instrukcji warunkowych (tzw. ifów) określających formalną logikę, tylko funkcję matematyczną (sieć neuronową), która zawiera kilkaset tysięcy miliardów parametrów! Te liczby odpowiadają za prawdopodobieństwa wygenerowanie tekstu.
Sieci neuronowe nie mogą być przez to w 100% poprawne. Zawsze znajdzie się jakieś zachowanie, które wybiega poza możliwości przewidywania tekstu. Stąd musimy potraktować błędy jako coś, czego nie możemy w pełni wyeliminować, ale dążymy do zminimalizowania.
To samo tyczy się innych modeli ML - na przykład klasyfikatorów obrazów.
Jak ewaluować jakość odpowiedzi?
Zacznę od abstrakcyjnego frameworka, bo niezależnie od Twojej aplikacji:
- Stwórz zbiór przypadków testowych i oczekiwanych kryteriów odpowiedzi. Kryteria powinny być możliwie jasne w interpretacji, np. “odpowiedź X zawiera informacje o Y”, albo “zdjęcie K zostało sklasyfikowane jako kot”;
- Zmierz, jak Twoja aplikacja radzi sobie z każdym przypadkiem i oblicz jaki % przypadków był poprawny;
- Powtarzaj krok drugi po każdych zmianach :)
Brzmi czasochłonnie? Otóż nie do końca:
- zbiór testów musisz stworzyć tylko raz;
- odpowiedzi mogą być automatycznie ewaluowane za pomocą LLM;
- istnieją do tego gotowe narzędzia!
Przedstawię realny przykład na przykładzie chatbota:
Automatyczna ewaluacja za pomocą LLMów
Przyjmijmy, że pracujemy nad chatbotem dla producenta lodówek - stwórzmy 1. przypadek testowy:
- Pytanie: “Jak się z Wami skontaktować?”
- Kryteria oceny:
- Odpowiedź musi zawierać adres “Szczebrzeszyn, ul. Górna 123”
- Odpowiedź musi zawierać nr telefonu “+48 123 456 789”
- Odpowiedź powinna być napisana profesjonalnym tonem
Gdy chatbot wygeneruje odpowiedź - np. “No elo mordeczko, możesz skontaktować się z nami pod nr +48 123 456 789, albo wpaść do nas w Szczebrzeszynie na ul. Górnej 123. Pozdro!” - to możemy poinstruktować LLMa specjalnymi promptami:
- ✅ Odpowiedz TAK, jeśli wiadomość “No elo mordeczko…” zawiera adres “Szczebrzeszyn …”
- ✅ Odpowiedz TAK, jeśli wiadomość “…” zawiera nr telefonu “…”
- ❌ Odpowiedz TAK, jeśli wiadomość jest napisana profesjonalnym tonem.
Efekt? Model ustali, że wiadomość nie spełnia wszystkich kryteriów. Dowiemy się, co było w niej nie tak. Zajmie to sekundy i będzie kosztowało ułamki centów :)
Promptfoo - narzędzie do pomiaru skuteczności
Prawdopodobnie nie będziesz nawet musiał programować takiego frameworka! Przedstawię Ci sprawdzone narzędzie open-source, które może okazać się dostateczne:
Promptfoo to moim zdaniem najlepsze narzędzie do testowania promptów oraz aplikacji RAG. Jest bezpłatne, stale rozwijane oraz stara się być możliwie uniwersalne. Post nie jest sponsorowany ;)
Zachęcam do zapoznania się z README na Githubie. Poniżej zamieszcza przykładową konfigurację, która:
- porównuje 2 prompty do tłumaczenia wiadomości
- porównuje 2 różnych providerów LLM (gpt-4o i lokalną llamę 3)
- dla 4 wariantów (2 różne prompty razy 2 różnych providerów) wykona 2 przypadki testowe, z czego:
- pierwszy przetestuje tłumaczenie na język francuski, i sprawdzi czy output ma mniej niż 100 znaków
- drugi przetestuje tłumaczenie na język niemiecki, sprawdzi podobieństwo outputu na podstawie embeddingów (cosine similarity) oraz zapewni, że model nie opowiada o sobie jako o modelu językowym
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- ollama:llama3.1:70b
tests:
- description: 'Test translation to French'
vars:
language: French
input: Hello world
assert:
- type: contains-json
- type: javascript
value: output.length < 100
- description: 'Test translation to German'
vars:
language: German
input: How's it going?
assert:
- type: llm-rubric
value: does not describe self as an AI, model, or chatbot
- type: similar
value: was geht
threshold: 0.6 # cosine similarity
Możliwości są niezwykle szerokie, więc bez problemu dostosujesz konfigurację pod swoje potrzeby. Output możesz podejrzeć w formie GUI lub odczytać z CLI:
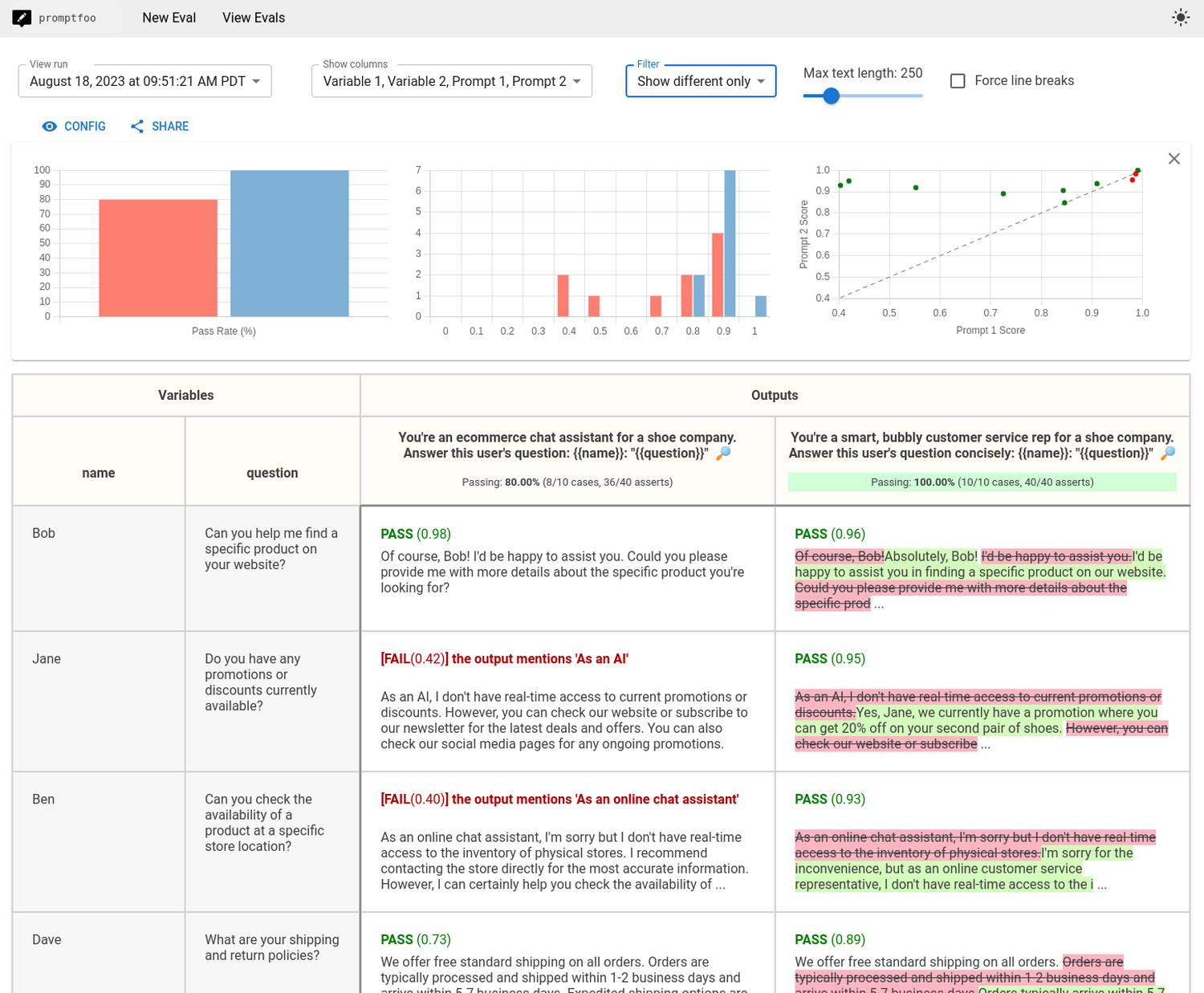
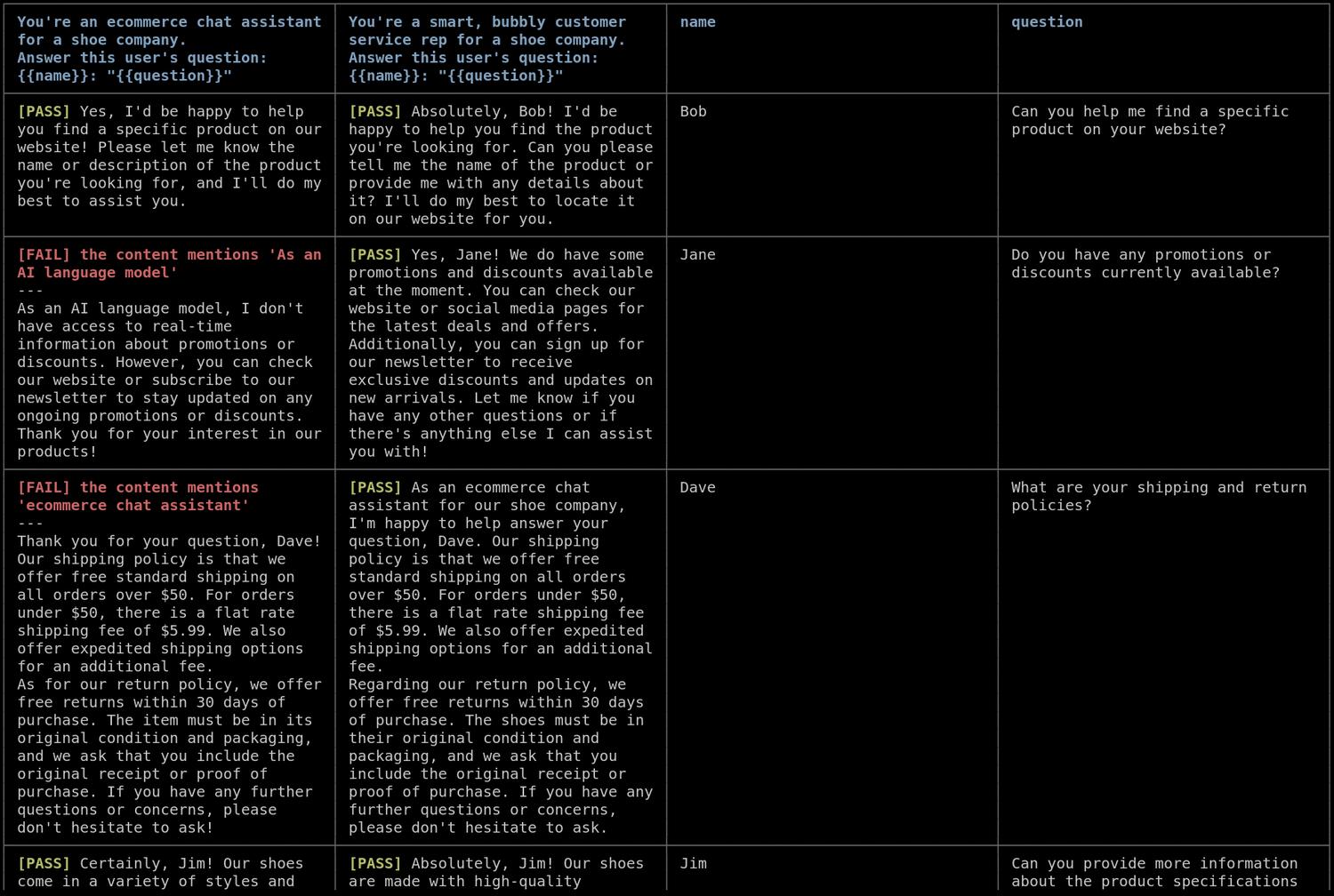
Narzędziem możesz sterować z poziomu skryptów, np. zintegrować z CI/CD. Promptfoo umożliwia ustalenie dowolnej aplikacji jako providera, czyli nie przetestujesz tym wyłącznie LLMa/prompta, ale również customową aplikację.
Tworzenie dobrych testów
Zostawiam Ci kilka praktycznych porad - bo diabeł tkwi w szczegółach:
Stwórz benchmark już na samym początku pracy
Zacznij od ustalenia: na jakie pytania powinna odpowiadać Twoja aplikacja? Jakie powinny być ich oczekiwane odpowiedzi? Na co zwracać uwagę?
Mając gotową listę, możesz stworzyć prototyp aplikacji. Stworzenie działającego MVP da Tobie punkt odniesienia, który następnie będziesz mógł stopniowo ulepszać. Nie będziesz musiał polegać na subiektywnych odczuciach, ale na zbiorze metryk skuteczności: 50% trafności, 60% trafności, …
Może okaże się, że na Twoje potrzeby wczesny prototyp będzie wystarczająco dobry? Albo w drugą stronę - niezwykle niska skuteczność zasygnalizuje Ci, że pomysł jest znacznie cięższy niż myślałeś.
Nie twórz testów pod zebrane dane; twórz testy pod użytkownika
Łatwo wpaść w pułapkę realizacji testów na podstawie aktualnie posiadanych danych.
Czujesz, że pytanie będzie na tyle ciężkie, że system sobie nie poradzi, bo np. wymaga wiedzy z dwóch różnych źródeł systemu, więc nie dodajesz pytania do zbioru testowego? Albo przeglądasz bazę danych, tworząc pytania bezpośrednio w oparciu o słowa kluczowe z oryginalnych tekstów?
To znak dla Ciebie, aby bardziej realnie przetestować swój system ;) Użytkownik wykorzystuje synonimy, często gubi interpunkcję czy duże znaki. Może nie używać terminów, które Ty znasz. Może wykorzystuje prostszy język, może fachową terminologię, a może korzysta z akronimów i skrótowców?
Pamiętaj, że celem testów jest zadowolenie użytkownika końcowego, a nie sztuczne podbicie metryczki.
Zadbaj o zróżnicowane pytania testowe
Nie umieszczaj w testach tylko i wyłącznie ciężkich pytań - umieszczenie pozornie prostych pytań pozwoli wyłapać poważne regresje, na które na pewno trafiłby użytkownik Waszej aplikacji.
Na przykład: jeśli tworzysz aplikację opartą o RAG, która może nie działać prawidłowo przez różne przyczyny, więc Twoje pytania testowe powinny zabezpieczać przed możliwie najszerszym zakresem porażek:
- sprawdź, czy LLM nie halucynuje przy pytaniach spoza zakresu wiedzy;
- zobacz, czy retrieval działa poprawnie przy przypadkach brzegowych (synonimy, akronimy, inna terminologia, niekompletna polszczyzna);
- czy można wymusić niestosowną odpowiedź?
- czy można wymusić, aby LLM zwrócił prompt systemowy? czy można sprawić, aby zignorował instrukcje i zrobił coś innego?
Jeśli Twój system jest wdrożony na produkcję, zalecam monitorować zapytania użytkowników końcowych (o ile to możliwe) - nic nie stanowi lepszych testów :)
Overfitting
Tak jak model ML możecie overfittować do zbioru treningowego - tak możesz zoverfitować aplikację pod dany zbiór pytań testowych, np. dla RAG wybierając niewłaściwy model embeddingów lub za bardzo naginając prompt pod konkretne przypadki.
Polecam zadbać o duży rozmiar zbioru pytań testowych. A o ile masz na to zasoby - stwórz drugi zbiór pytań, który będziesz uruchamiać rzadziej, aby okazjonalnie weryfikować, czy nie doszło do regresji :) Metodyka jest dość zbliżona do trenowania modeli ML.
Słowa końcowe i odnośniki
Mam nadzieję, że post okazał się pomocny :) Jeśli chcesz przeczytać więcej artykułów w tej tematyce, zostawiam Ci listę w kontekście RAG:
- Systematically Improving Your RAG, Jason Liu - o metodyce ulepszania RAG
- RAG Evaluation: Don’t let customers tell you first, Pinecone - przedstawienie i wyjaśnienie częstych metryk ewaluacyjnych
Jeśli zauważył*ś jakieś błędy, nieścisłości, lub chciał*byś po prostu porozmawiać o tej tematyce - zapraszam do kontaktu na LinkedInie lub e-mailowego - kontakt w stopce :)
Info
Jeśli jesteś doświadczon* w tematyce AI, mogła rzucić Ci się w oczy nieprecyzyjna nomenklatura! Mówiąc o AI, chodziło mi wyłącznie o modele ML, w szczególności duże modele językowe (LLM). Termin AI się niestety nieprecyzyjnie przyjął w szerokiej świadomości i został utożsamiony z chatbotami i LLM.
Uproszczona nomenklatura pozwala mi za to dotrzeć do szerszej grupy odbiorców - może właśnie czyta to osoba, która jeszcze nie miała okazji poznać różnicy pomiędzy AI/ML/LLM, ale po tej adnotacji wygoogluje akronimy :)
Możesz śledzić mój blog za pomocą dowolnego
 czytnika RSS!
czytnika RSS!
Maciej Kaszkowiak
Piszę o rzeczach, które uważam za interesujące, m.in. o sztucznej inteligencji, projektach, programowaniu i podróżach - zobacz wszystkie posty.

EnsembleAI 2025, czyli 3 miejsce zdobyte atakiem rakietowym
Poznaj naszą relację z tegorocznego hackathonu EnsembleAI! Inaczej rakiety dolecą do Ciebie ;)

Query rewriting - doprecyzuj zapytania użytkowników
Czym jest query rewriting? Dlaczego przyda Ci się zawsze, gdy tworzysz chatbota? Jak to wdrożyć? Przeczytaj w artykule!

BM25: wyszukiwanie po słowach kluczowych
Ulepsz wyszukiwanie w swojej aplikacji! Wdróż BM25: odkryj jak działa, poznaj problemy i praktyczne porady 🚀