BM25: keyword search
Improve search in your application! Implement BM25: discover how it works, learn about potential issues, and get practical advice 🚀

What is BM25?
BM25 is a function that scores how well documents match a user’s query. If words from the query appear in the document, the document receives points.
BM25 is useful wherever keyword search is needed. It is used as the default algorithm in ElasticSearch or in RAG applications for hybrid search combined with embeddings.
Understanding the mechanism and implementation tricks is extremely useful - especially for morphologically rich languages like Polish!
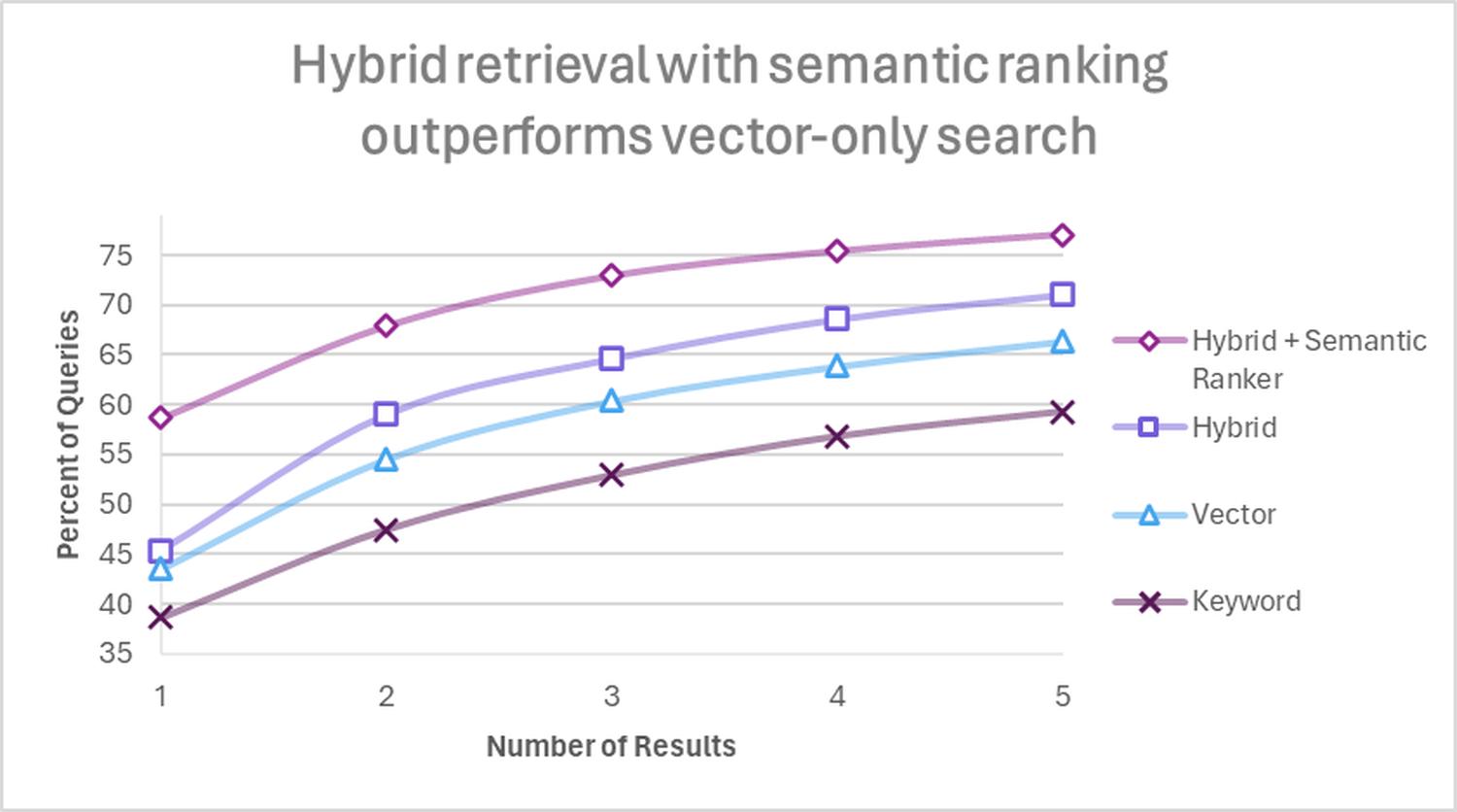
How does BM25 work?
The algorithm analyzes the frequency of specific keywords in a set of documents.

The formula might look overwhelming ;) I will explain what it implies, and for those interested in the formal definition, I refer you to Wikipedia and an excellent article comparing TF/IDF and BM25.
Key principles
Documents and queries are first divided into terms: let’s assume 1 word = 1 term. [1]
The rarer the matched words are in the document set, the more points they yield:
- If we are searching a bookstore inventory, for the query “eclecticism book”, matches for the rarer word “eclecticism” will be scored higher than matches for the word “book”, as it might appear often in a book store.
- Common words will score significantly lower: e.g., in the phrase “what for dinner”, matching “what to throw for the grill” will be much weaker than “ideas for dinner”, as the words “what” and “for” appear more often than “dinner” in sentences.
The more often a word appears in a document, the more points the document receives. However, there is a saturation point. For the query “cat”, an article about cats will be scored higher than an encyclopedia listing all animals:
- The article mentions “cat” 20 times in 2 pages of text.
- The encyclopedia mentions “cat” 30 times, but spread over 100 pages of text. This means that the article is more keyword-dense for the “cat” word.
BM25 also ignores the relative position of words in the document. For the sentence:
- “where is the red elephant?”
The following sentences would have identical matches:
- “red notebook, black elephant”
- “red elephant, black notebook”
As each word is considered individually, it can miss their context.
Info
[1] Documents are effectively divided into terms - usually these are words, but we can just as well use a different split.
- We can split documents into
n-grams, which group words together:
bi-gramsare combinations of two wordstri-gramsare combinations of three words
This solves the previously mentioned red elephant problem!
- We can split documents into tokens using, for example, the
tiktokentokenizer.
This reduces the need for stemming/lemmatization (more on that in a moment).
Both approaches have their trade-offs, so I recommend Googling and experimenting ;)
Pre-processing
For BM25 to work effectively, input data pre-processing is required. Here are the essential steps with examples:
Lowercasing
BM25 is case-sensitive by default: it distinguishes between uppercase and lowercase letters. The token “Red” will not be associated with the token “red”.
If this is not desirable in your application, then converting text to lowercase (lowercasing) will eliminate this problem. However, if you are processing serial codes that distinguish between cases and want to allow precise searching, introducing lowercasing might worsen results!
Hence, it is always worth considering: do we want to introduce pre-processing?
# Before changes
documents = ["The Sun is green"]
query = "What color is the sun"
search_bm25(documents, query) == []
# No documents - Sun vs sun
# After changes
documents = ["the sun is green"]
query = "what color is the sun"
search_bm25(documents, query) == ["the sun is green"]
# Match on the word sun
Note
Note that the input data must be processed in the identical way as the document data in the index. If, for example, we want to lowercase words - we must do this for both the user query and the documents. This applies to every step.
Removing Stopwords
Info
Stopwords are words commonly occurring in a given language, for example: “this”, “in”, “how”, “with”, “on”.
Removing stopwords means the most frequent words in a language are deleted:
remove_stopwords("what is the weather today?") == "weather today?"
remove_stopwords("the dog is very happy") == "dog happy"
After removing stopwords, the sentence “what is the weather today?” (jaka jest pogoda dzisiaj?) might not match “the dog is very happy” (pies jest bardzo szczęśliwy) solely on the common word “is”, preventing irrelevant matches.
There is no universal list of stopwords, as they differ between languages (and how strict the list should be) - here’s an example list for the English language.
Issues
Removing stopwords has its problems:
- Stopwords vary by language. If we used an English stopword list for a Polish search query, we might not find information about bridges - because “most” (bridge in Polish) is a stopword in English (meaning “greatest amount”)! This means that if we create a BM25 index operating on multiple languages, we should correctly identify the language before selecting the appropriate list. The same applies to user queries.
- Stopwords can have semantic meaning in a sentence - when saying “The Rock”, we mean the American actor; when saying “rock”, we mean a stone.
Furthermore: removing stopwords is not strictly necessary with BM25. The algorithm scores unique words higher, so with a sufficiently large number of documents, commonly occurring stopwords will contribute very few points. Irrelevant matches will have a low score.
As with all steps: introduce such processing for your dataset and test how it affects results :)
Stemming and lemmatization
A key problem (especially in inflected languages like Polish) - for BM25, “pies” (dog), “psy” (dogs), and “psach” (about dogs) are 3 different words! Let’s consider the following sentences:
- “kleszcz na psie” (tick on a dog)
- “poradnik: zwalczanie kleszczy u Twojego psa” (guide: fighting ticks on your dog)
These sentences won’t match in Polish - “kleszcz” is not “kleszczy”, and “psie” is not “psa”.
Two methods that can solve this problem are stemming and lemmatization.
Stemming involves extracting the root from a word, usually by chopping off the inflectional ending. The result is not necessarily a correct word, but it allows for comparing similar words:
stemmer('fishing') == 'fish'
stemmer('fished') == 'fish'
stemmer('fisher') == 'fisher'
stemmer('argument') == 'argu'
stemmer('arguments') == 'argu'
stemmer('relativity') == 'relat'
Lemmatization involves extracting the base form, e.g., the infinitive for verbs or the singular for nouns:
lemmatization('fishing') == 'fishing'
lemmatization('fished') == 'fish'
lemmatization('is') == 'be'
lemmatization('better') == 'good'
Lemmatization is more resource-intensive than stemming, but usually achieves better results. For the Polish language, we can use tools like PoLemma for lemmatization and Stempel for stemming.
Returning to the example - after applying lemmatization, our BM25 algorithm will be able to match the sentences:
- “kleszcz na psie” > “kleszcz na pies”
- “poradnik: zwalczanie kleszczy u Twojego psa” > “poradnik: zwalczyć kleszcz u twój pies”
Removing diacritics
In pre-processing, we can also remove language-specific characters (diacritics), which eliminates mismatches between “zażółć gęślą jaźń” and “zazolc gesla jazn”, which are the same sentence. However - if we add this processing step, the word “łoś” (moose) begins to be associated with the lottery “los” (ticket/fate). It’s a trade-off!
Typos and synonyms
BM25 will not associate the word “dog” with “dag” (typo); nor will it associate “car” with “automobile”. At the time of writing this article, I don’t have a solution, but I’m highlighting the problem ;)
Implementing BM25
Using Python as an example - you can use one of the ready-made libraries, specifically:
- rank-bm25 is the most popular library, but not the best;
- a much better choice is bm25s, which is several hundred times faster than
rank-bm25and supports, among other things, saving the index in memory-mapped files.
Another good option is an index in a database - for example ParadeDB, which is Postgres with the pg_search extension installed, enabling BM25 indexing on a text column. The extension also enables more complex queries. The project is licensed under AGPL v3.0.
Other databases with BM25 support that I know of, but haven’t tested, are ElasticSearch and Weaviate.
Tip
If your chosen database/library doesn’t support appropriate pre-processing, implement the processing on the application side and pass already processed documents to the BM25 index.
Remember about benchmarks
Remember to create a relevance benchmark for your search engine before starting work, using selected metrics like recall@3 / recall@5. This will allow you to determine whether the introduced changes improve or worsen the quality of your application - don’t trust your intuition!
recall_a = test_recall_bm25_no_preprocessing(test_set)
# 85%
recall_b = test_recall_bm25_with_inappropriate_preprocessing(test_set)
# 67%
# Conclusion: version A > version B
Final words and links
I hope this post proved helpful :) If you want to read more articles on this topic, here is a list:
- Better Sparse Retrieval: Extending BM25 With Subwords, Evan Harris - article presenting improvements to BM25, with the concept of using tiktoken as an alternative to stemming;
- Understanding TF-IDF and BM-25, Rudi Seitz - excellent explanation of differences between TF/IDF and BM25;
- What Are Stemming and Lemmatization?, IBM - stemming vs lemmatization
If you notice any errors, inaccuracies, or would just like to chat about this topic - feel free to contact me on LinkedIn or via email - you can find the address in the footer :)
You can follow my blog with any
 RSS reader!
RSS reader!
Maciej Kaszkowiak
I try to write about interesting things, such as artificial intelligence, created projects, and travel - see all posts.

Query rewriting - refine user queries
What is query rewriting? Why is it useful whenever you build a chatbot? How to implement it? Read the article!

Even your cat poem generator requires proper tests
Benchmark your AI application. Learn why and how to do that!

Overview of best OCR tools
Overview of tools for effective OCR on PDF files. This article will help you improve the quality of text extracted from your documents! 📄