Embeddingi w pigułce
Czym są embeddingi, z których prawdopodobnie korzystasz na codzień? Dowiedz się w artykule - wiele buzzwordów przestanie być czarną magią 🧙

Przyjmijmy, że chcemy, aby nasz komputer przetworzył jakiś tekst.
Zastosowanie może być dowolne:
- prosimy ChatGPT o korektę naszej wiadomości,
- próbujemy przetłumaczyć wiadomość,
- lub np. wykorzystujemy algorytm do rozpoznania emocji w tekście.
We wszystkich podejściach pojawia się jeden problem.
Jak komputer, myślący liczbami, bajtami i bitami, może przetworzyć tekst złożony z ludzkiej mowy, czyli słów i liter?
Otóż, przed rozpoczęciem przetwarzania, komputer tłumaczy tekst na swój język. Zamienia słowa i zdania na zbiór liczb o określonej strukturze, zwany embeddingami :)
Czym są embeddingi?
Embeddingi to reprezentacja tekstu [1] w postaci N-wymiarowego wektora. Tekstem może być słowo, zdanie, kilka zdań, czy też kilka paragrafów.
Przykładowo, wyraz “Kot” może zostać zamieniony w wektor [0.123, 0.892, 0.004, ..., 0.572] który zawiera 300 liczb z wartością pomiędzy -1 a 1.
Zdanie “Bardzo lubię jeść czekoladę w adwent” również zostanie zamienione w wektor o identycznej strukturze - otrzymamy 300 liczb z wartością pomiędzy -1 a 1.
Same wartości wektorów są nieczytelne dla nas, jako ludzi. Przykładowo, nie jesteśmy w stanie odczytać żadnych informacji z tego, że otrzymaliśmy -1 na 54tej pozycji wektora, lub 0,5 na 13tej pozycji.
Info
[1] Embeddingi mogą być również generowane dla zdjęć, filmów czy audio. Sam koncept embeddingów odnosi się do zamiany skomplikowanych danych (jak tekst czy zdjęcie) w wektor liczb.
Aby artykuł pozostał prosty, omówię wyłącznie ich znaczenie tekstowe, bo jest aktualnie najczęściej wykorzystywane :)
Co nam dają embeddingi?
Porównywanie dwóch wektorów pozwala nam określić, jak bardzo odpowiadające im słowa / zdania są semantycznie podobne.
Nie chodzi jednak o samą konstrukcję słowa - czy “prąd” jest podobny do “prad”, “prda”, czy “prdą” - jak w tradycyjnym wyszukiwaniu opartym o słowa kluczowe.
Podobieństwo semantyczne jest ustalane po ludzku - czy słowa / zdania mają podobne znaczenie.
Porównywanie słów - o historii embeddingów
word2vec
Przedstawię przykład w oparciu o pionerski algorytm word2vec, opublikowany w 2013 przez Tomáša Mikolova z Google.
Algorytm word2vec powstał poprzez przetworzenie bardzo dużego korpusu tekstu. Umożliwiło to samoistne znalezienie podobieństw, bez konieczności nadzoru i dodatkowej pracy ze strony badaczy (unsupervised learning).
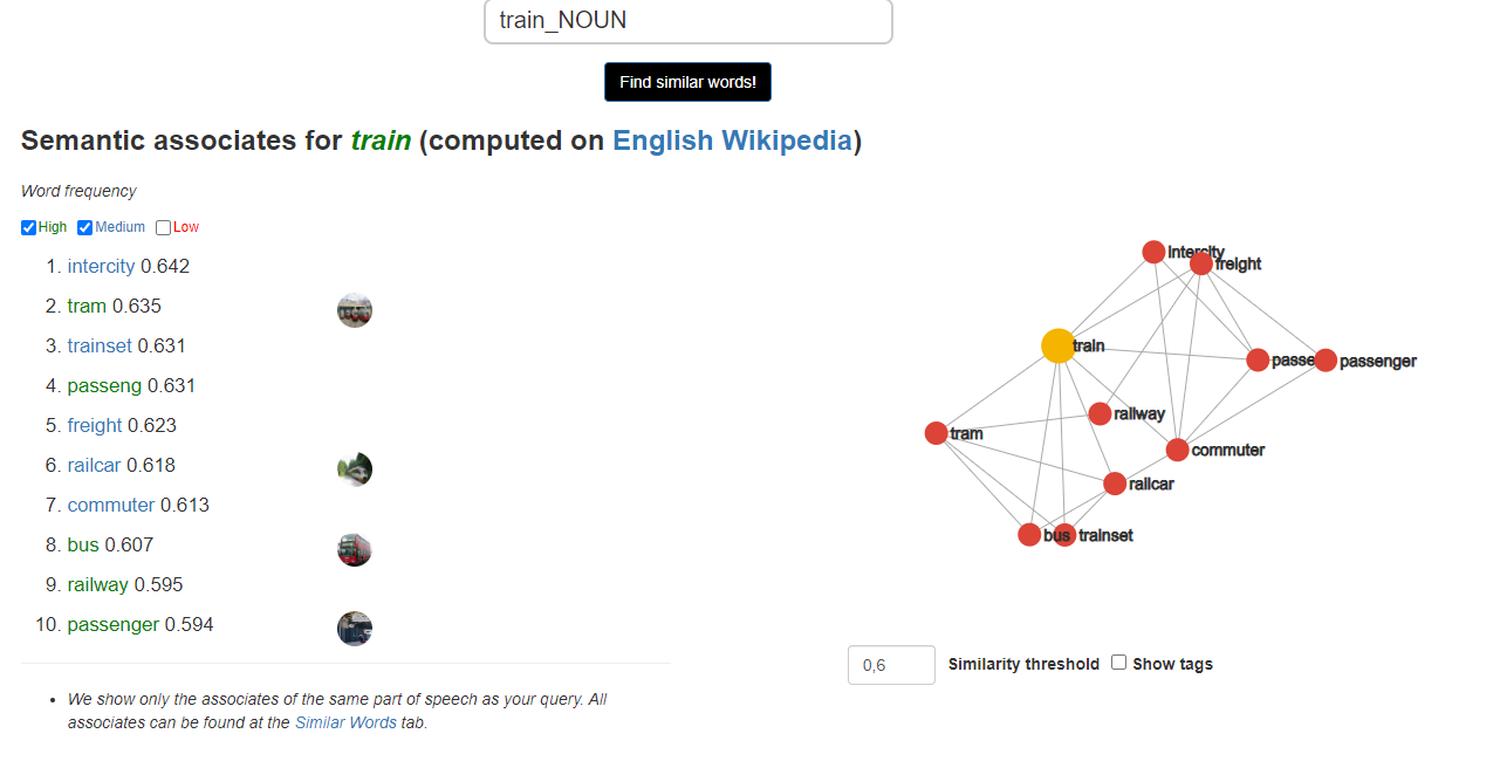
Słowo “train” zostaje określone jako podobne do “intercity”, “tram”, “trainset”, “freight”, “railcar”, “passenger”, “bus”:
- “train” - “tram”/“bus”, bo komunikacja publiczna;
- “train” - “freight”, bo kolej towarowa;
- “train” - “passenger”, bo kolej pasażerska; …
Pomimo słów o zupełnie odmiennej konstrukcji, algorytm trafnie oddał ich znaczenie przez ustalenie podobieństw.
Wyobraźcie sobie, jak bardzo ułatwia to wyszukiwanie w Internecie! Aby znaleźć wyniki związane z “transport miejski”, “miejskie przedsiębiorstwo komunikacyjne” i “rozkład jazdy”, wystarczy, że wpiszemy “komunikacja publiczna”. Nie bez powodu wiodący research (zarówno dla word2vec, jak i poźniej omawianego BERT) był prowadzony przez Google.
Mechanizm porówywnywania embeddingów to prosta operacja matematyczna. Mierzymy odległość pomiędzy dwoma punktami - tylko zamiast dwóch lub trzech wymiarów, jak to miało miejsce na matematyce, operujemy na N wymiarach, gdzie N jest rozmiarem wektora.
Kluczowy wniosek - porównywanie istniejących embeddingów jest znacznie szybsze od generowania nowych.
Co więcej, wektorami w word2vec można manipulować:
Jeśli do jednego wektora dodamy drugi wektor, a następnie odejmiemy trzeci wektor, to może się okazać, że wynik jest bardzo zbliżony do istniejącego słowa! [3]
- Wynik “man” + “queen” - “woman” jest najbardziej zbliżony do “king”
- Wynik “Rome” + “France” - “Paris” jest najbardziej zbliżony do “Italy”
- Wynik “Man” + “Sister” - “Woman” jest najbardziej zbliżony do “Brother”
Niesamowite, prawda? :)
Porównywanie zdań
Powyższe przykłady przedstawiłem dla pojedynczych słów, ale algorytm działa równie dobrze dla zdań, czy także zbiorów zdań.
Przyjmijmy, że mamy bazę wiedzy, w postaci 3 następujących zdań:
- Zbliżają się święta!
- Masło orzechowe jest dobrym źródłem białka.
- Maciej ma na sobie czerwony świąteczny sweter…
Mamy również pytanie, dla którego chcemy znaleźć najbardziej podobne zdanie:
- Jak polepszyć dietę?
Gdy:
- wygenerujemy embeddingi dla wszystkich 4 zdań
- oraz porównamy wszystkie 3 pary (embedding pytania) - (embedding zdania)
Dla każdej pary otrzymamy liczbową wartość podobieństwa - im wyższa, tym bardziej zbliżone są zdania.
Najbardziej trafnym dopasowaniem do pytania “Jak polepszyć dietę?” prawdopodobnie okaże się zdanie “Masło orzechowe jest dobrym źródłem białka.” - pomimo tego, że nie pokrywają się żadne słowa kluczowe!
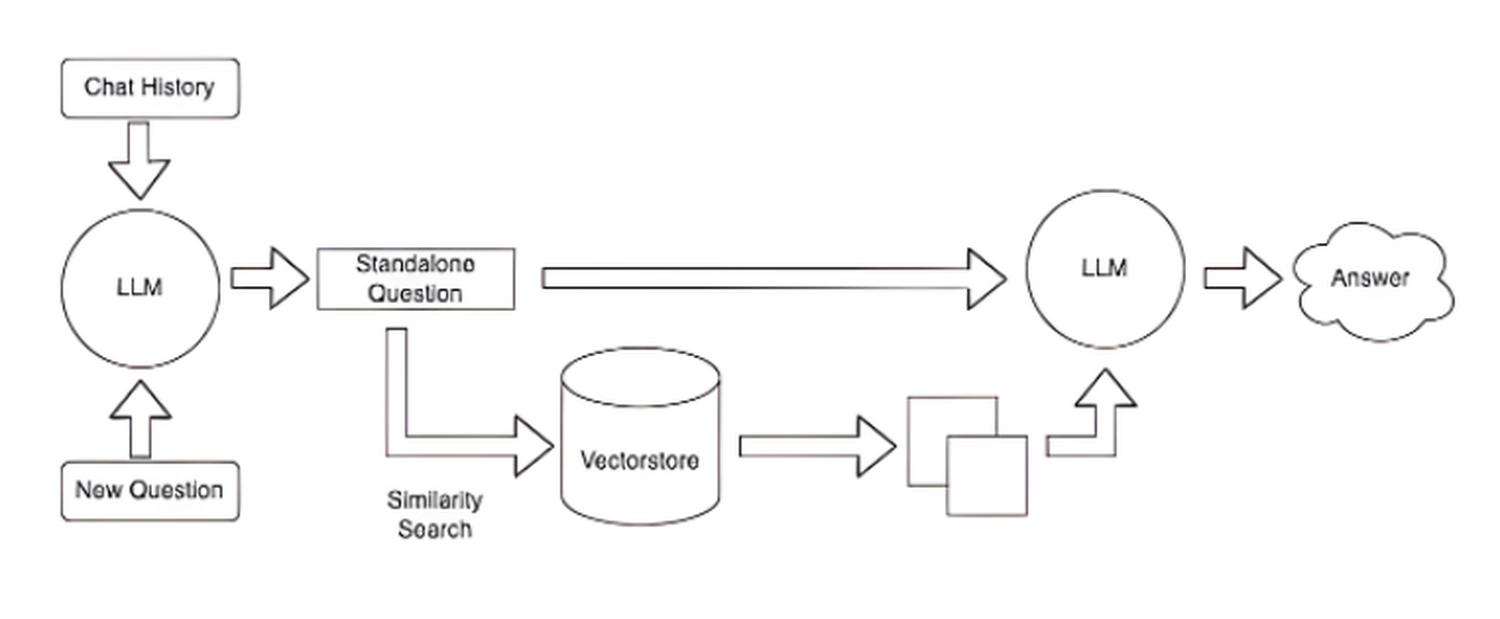
Ta technika jest wykorzystywana chociażby w Retrieval Augmented Generation, które umożliwia nam znalezienie najbardziej dopasowanych dokumentów do pytania użytkownika, a następnie udzielenie na ich podstawie odpowiedzi przez LLM (jak np. ChatGPT). Jeśli nie znasz tej metody: zachęcam do zapoznania się z artykułem o RAG!
Nowsze algorytmy
Głównym problemem word2vec jest słabe rozpoznawanie kontekstu dla wyrazów. Przykładowo, w zdaniach:
- apple and banana republic are american brands
- apple and banana are popular fruits
Ten sam embedding zostanie wygenerowany dla słów “apple” i “banana”, pomimo że w pierwszym zdaniu odnoszą się do firm, a w drugim do owoców. [12]
word2vec zostało szybko zastąpione przez nowsze modele, generujące embeddingi o lepszej jakości.
Kluczowe jest, aby porównywać ze sobą embeddingi uzyskane wyłącznie tą samą metodą. Zestawienie ze sobą embeddingów wygenerowanych przez dwa różne modele, nie da nam żadnego wymiernego rezultatu.
BERT
W 2018 roku naukowcy z Google przedstawili model BERT, oparty o architekturę transformerów. [5]
W odróżnieniu od word2vec, w BERT embeddingi słów są zależne od kontekstu. Co więcej, BERT umożliwił embeddowanie całych zdań! Dla poniższych zdań:
- apple and banana republic are american brands
- apple and banana are popular fruits
Odmienne znaczenie tych samych słów “apple” oraz “banana” nie wpłynie już negatywnie na jakość embeddingów.
Natomiast ze względu na inną architekturę, BERT uniemożliwia operowanie na embeddingach, jak w powyższych przykładach - czy to przez wizualizacje sąsiadów, czy przez matematykę na wektorach. [12] Na szczęście to zupełnie nie jest potrzebne w praktyce :)
SBERT
BERT zadziałało doskonale dla pojedynczych słów, ale embeddingi całych zdań nie były jeszcze doszlifowane.
W 2019 roku powstał model SBERT, ulepszający model BERT i ułatwiający porównywanie poszczególnych zdań. [6]
SBERT dla każdego zdania generuje nam wektor, czyli embedding, na którym możemy operować poza siecią neuronową. Przyspieszenie procesu względem BERT przy zachowaniu jakości okazało się gigantyczne, ponieważ ówczesne rozwiązania SoTA wymagały kalkulowania podobieństwa poprzez inferencję sieci BERT. SBERT umożliwił wykonywanie prostego podobieństwa cosinusowego na wygenerowanych wektorach. Zacytuję tutaj oryginalny paper:
BERT (Devlin et al., 2018) and RoBERTa (Liu et al., 2019) has set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead: Finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT. The construction of BERT makes it unsuitable for semantic similarity search as well as for unsupervised tasks like clustering.
In this publication, we present Sentence-BERT (SBERT), a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
Zwiększanie trafności porównywania zdań
Wrócę jeszcze do samego porównywania zdań pod kątem podobieństwa. To aktualnie prawdopodobnie najczęste zastosowanie embeddingów.
Bi-encoder
Najprostszą metodą jest porównywanie odpowiadającym im embeddingów za pomocą cosine similiarity. Jest to tak zwany bi-encoder. To dokładnie ten sam mechanizm, co opisałem dla przykładu SBERT :) Jest to również aktualnie najczęściej stosowana metoda w aplikacjach GenAI - z API otrzymujemy embeddingi, które zapisujemy w bazie, a następnie wykonujemy na nich operacje.
Metoda jest skuteczna i szybka, jednak nie jest stricte najlepsza pod kątem jakości.
Cross-encoder
Znacznie lepszą jakość oferuje nam cross encoder: [13]
- Bi-encoder zwraca dla jednego fragmentu wektor, który następnie możemy porównać z dowolnym innym wektorem.
- Cross-encoder zwraca dla dwóch fragmentów wartość pomiędzy 0 a 1 wskazującą na to, jak zbliżone są dwa wyrazy, zdania, czy też dokumenty.
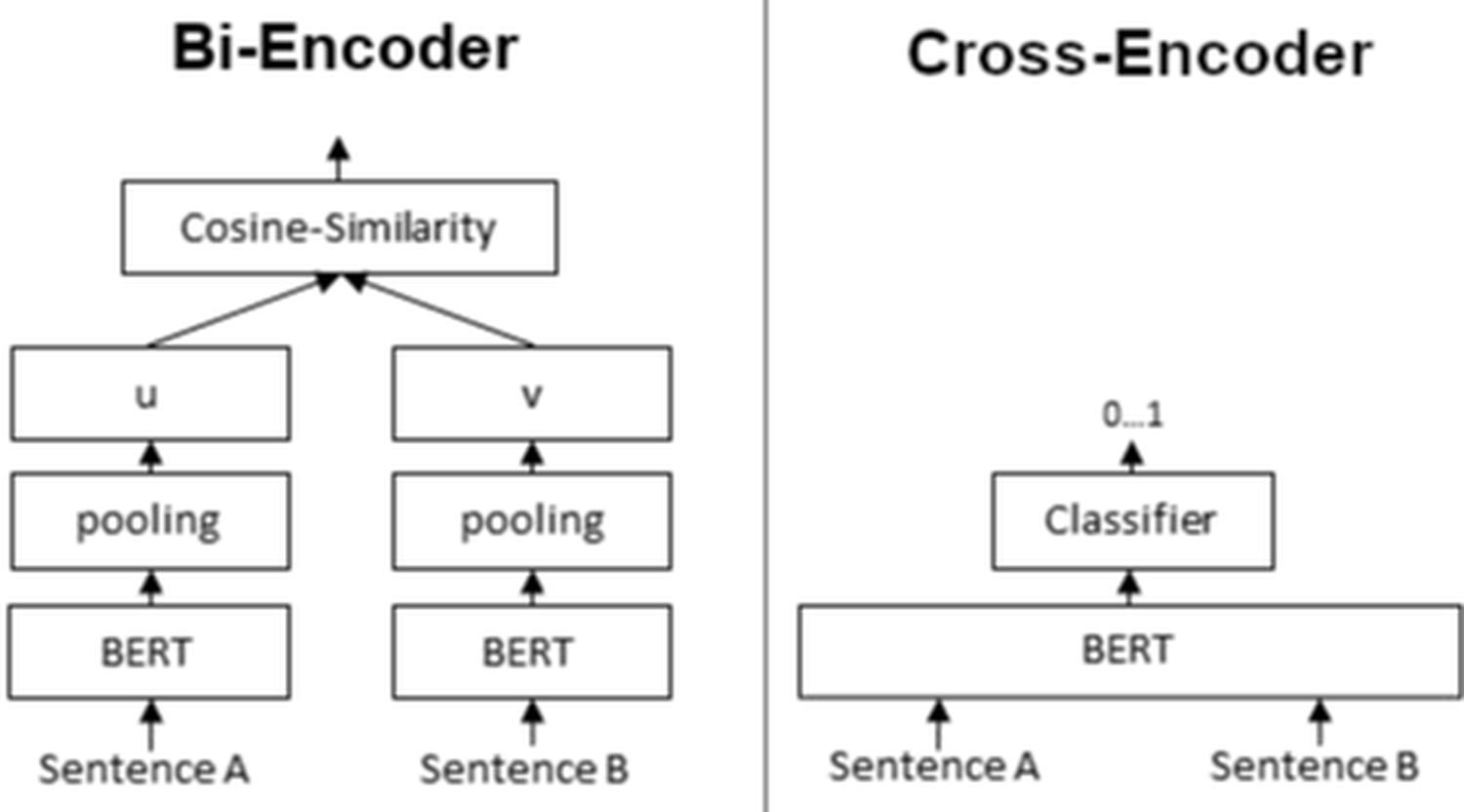
Problemem jest jednak prędkość. Nie jesteśmy w stanie w rozsądnym czasie uruchomić modelu na każdej parze zdań (co wskazuje również cytat z paperu SBERT).
Jak więc wykorzystać cross-encoder do polepszenia jakości?
Re-ranking
Na ratunek przychodzi re-ranking: to technika, która umożliwia nam wykorzystanie cross-encodera do wybrania najlepszego fragmentu spośród zbioru kandydatów wybranych przez bi-encodera. [14]
- W pierwszej kolejności szukamy dla naszego pytania duży zbiór (np 100) najtrafniejszych tekstów;
- Następnie wykorzystujemy Cross Encoder, aby zbadać podobieństwo pomiędzy pytaniem, a otrzymanymi tekstami.
Znacząco zwiększa to trafność wyszukiwania przy stosunkowo niewielkim wzroście czasu oczekiwania za odpowiedzią. Wzrost jakości jest bardzo odczuwalny przy dużych zbiorach tekstów.
Można potraktować to jako wstępny przesiew kandydatów (wysoki recall), z którego wyłaniamy najlepsze dopasowania (zwiększamy accuracy).
Demonstrując na przykładzie opartym o dane z Wikipedii, bi-encoder ‘multi-qa-MiniLM-L6-cos-v1‘, cross-encoder ‘cross-encoder/ms-marco-MiniLM-L-6-v2‘ oraz wyszukiwanie leksykalne BM25: [15]

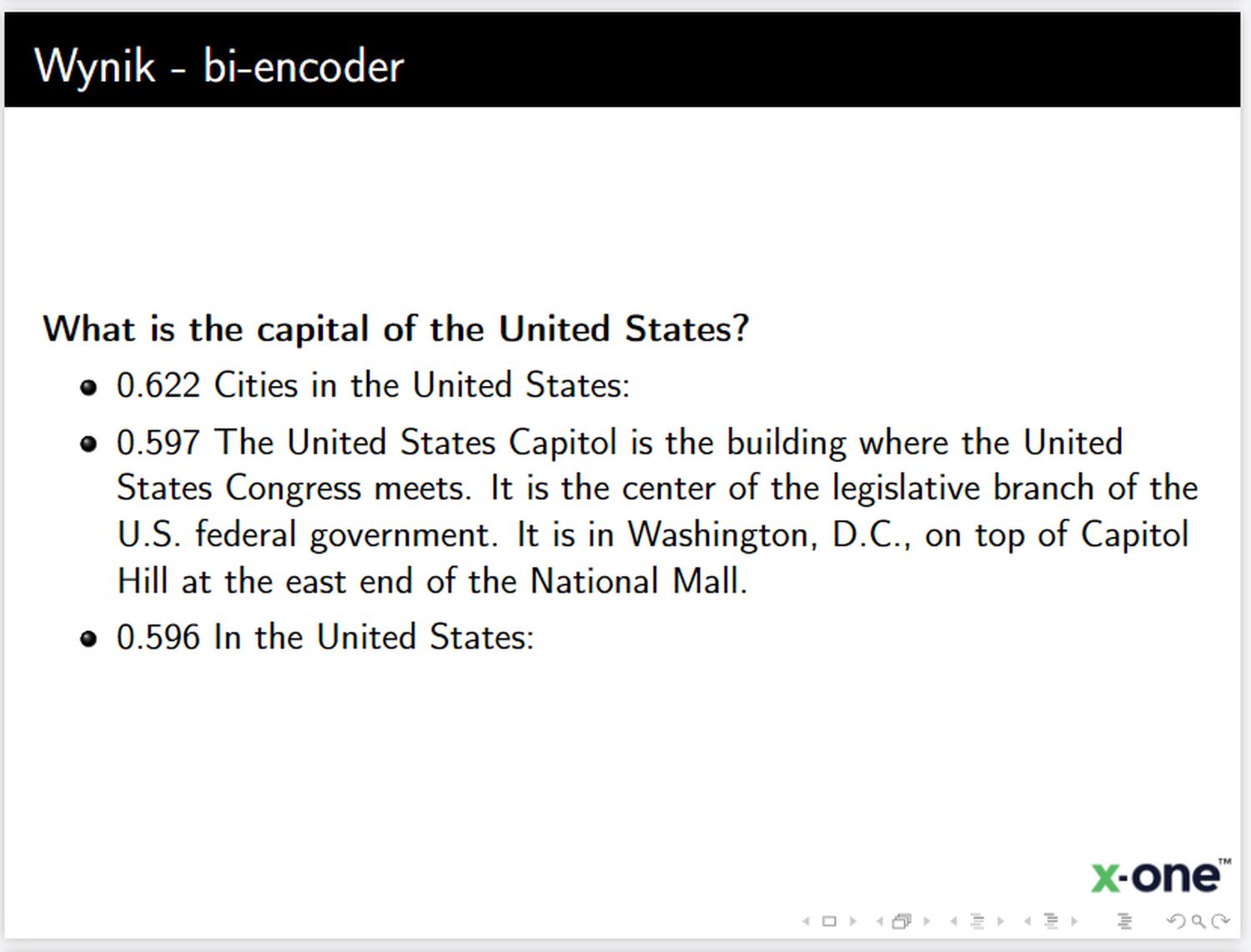
Odpowiedzi otrzymane po re-rankingu są znacznie lepsze od odpowiedzi znalezionych przez BM25 i sam bi-encoder:

Fragmenty po re-rankingu nawiązują bezpośrednio do naszego pytania - technika działa :)
Zwiększanie szybkości porównywania
Wyszukiwanie trafnych embeddingów staje się czasochłonne przy dużych zbiorach danych.
Najprostszy sposób, czyli iterowanie po kolejnych wektorach, ma złożoność czasową liniową względem rozmiaru naszej bazy embeddingów.
10 milionów embeddingów wymaga porównania 10 milionów wektorów z wektorem otrzymanym dla naszego pytania.
Z tego powodu powstały bazy wektorowe, które przyśpieszają proces wyszukiwania. [16]
Należy wspomnieć, że przyśpieszanie wyszukiwania jest procesem stratnym. Nie jesteśmy w stanie utrzymać perfekcyjnej jakości wyszukiwań, jednocześnie redukując prędkość. Często jest to jednak akceptowalny trade-off w produkcyjnych systemach.
Efektywne przechowywanie wektorów jest możliwe nawet w Postgresie z wykorzystaniem pgvector. [17]
Przykład w Pythonie
SBERT jest dostępny pod Pythonową biblioteką SentenceTransformers. Wykorzystanie wymaga zaledwie kilku linijek kodu:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
emb1 = model.encode("This is a red cat with a hat.")
emb2 = model.encode("Have you seen my red cat?")
cos_sim = util.cos_sim(emb1, emb2)
print("Podobieństwo: ", cos_sim)
Embeddingi możemy generować wykorzystując wyłącznie procesor. Posiadanie karty graficznej przyspieszy ten proces, jednak nie jest wymagane do inferencji (odpytywania) modelu.
Jaki model wykorzystać do wygenerowania embeddingów?
Model możemy wybrać w oparciu o MTEB leaderboard, który przedstawia jakość poszczególnych modeli dla różnych zadań i języków - w tym języka polskiego! MTEB to akronim od Massive Text Embedding Benchmark.
Ranking możemy przefiltrować po zadaniach takich jak np. klasyfikacja, reranking czy retrieval.
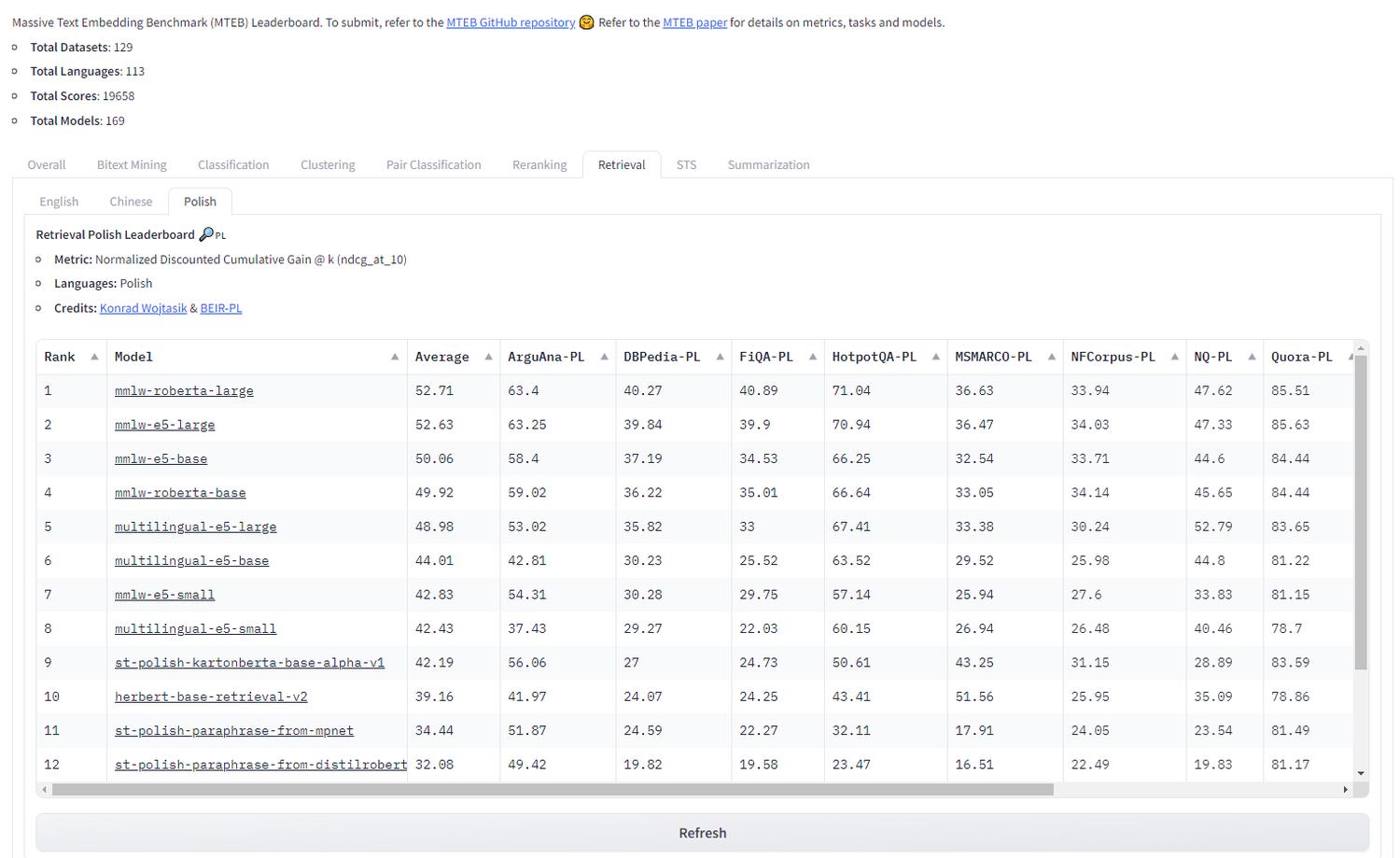
Operując na przykładzie wyszukiwania najbardziej zbliżonego zdania do pytania, aby znaleźć odpowiedni model, powinniśmy wybrać zakładkę “Retrieval” oraz język polski.
Specjalistyczne zastosowania
Jako ciekawostkę: możemy dotrenować model embeddingów na własnym korpusie tekstu. Takie rozwiązanie usprawnia wyniki, ponieważ model ma szansę nauczyć się specjalistycznego słownictwa w odpowiednim kontekście.
Firma odpowiedzialna za Kelvin Legal wytrenowała swój model na korpusie dokumentów prawniczych oraz finansowych, znacząco przewyższając trafność pozostałych modeli dla związanych z nimi pytaniami. Ich najmniejszy model radzi sobie lepiej z dokumentami prawniczymi od największego modelu z OpenAI! [11]
To wszystko na dzisiaj. Dzięki za przeczytanie artykułu! :)
Możesz śledzić mój blog za pomocą dowolnego
 czytnika RSS!
czytnika RSS!
Maciej Kaszkowiak
Piszę o rzeczach, które uważam za interesujące, m.in. o sztucznej inteligencji, projektach, programowaniu i podróżach - zobacz wszystkie posty.

EnsembleAI 2025, czyli 3 miejsce zdobyte atakiem rakietowym
Poznaj naszą relację z tegorocznego hackathonu EnsembleAI! Inaczej rakiety dolecą do Ciebie ;)

Query rewriting - doprecyzuj zapytania użytkowników
Czym jest query rewriting? Dlaczego przyda Ci się zawsze, gdy tworzysz chatbota? Jak to wdrożyć? Przeczytaj w artykule!

BM25: wyszukiwanie po słowach kluczowych
Ulepsz wyszukiwanie w swojej aplikacji! Wdróż BM25: odkryj jak działa, poznaj problemy i praktyczne porady 🚀