Even your cat poem generator requires proper tests
Benchmark your AI application. Learn why and how to do that!

Why measure effectiveness at all?
Let’s imagine the following situation:
You and your team are responsible for developing the latest AI application: a generator of poems about cats.
It’s a calm Friday morning. Your <client / user / tester> reports a critical bug: the application suddenly wrote a poem about a dog! You are tasked with fixing this, so you adjust the mechanism for the found case. You re-test the attached question and… it works, so you deploy the fix to production :)
But does it really work? You don’t have a test suite, so:
- you don’t know that fixing 1 case caused erroneous answers in 10 other cases;
- after the changes, your application occasionally started generating poems in Chinese - you don’t know why, but you have to prepare another patch;
- a previously reported bug, which you have fixed a month ago, suddenly started appearing in the system again;
- you are unable to determine if your application is actually improving - after all, new errors keep appearing! How will you prove that the changes are actually improving the application?
And this is where tests come in to solve your problems! Not just when generating poems about cats, but specifically in real applications: chatbots, agentic systems, document processing tools, etc.
Tests in AI applications are necessary
Introducing tests will help you establish that change X improved the application’s effectiveness from 80% to 85%, and the subsequent change Y worsened effectiveness from 85% to 73%. Thanks to this:
- you will be able to clearly determine whether the application’s effectiveness is improving, or if it has weak points;
- you will prevent the unconscious introduction of regressions, i.e., deterioration of response quality or increased frequency of errors;
- furthermore: by creating tests, the requirements of your application and what should be your priority will clarify very quickly.
I believe that in AI-based applications, tests are a necessity! You cannot completely skip them, e.g., by trying to minimize costs. This will only work if your application doesn’t have to be good, or you foresee that it won’t go anywhere near production - then the way is clear ;)
My CRUD is 100% correct and has no errors. Why can’t I do that with AI?
Traditional applications (without AI) rely on logic that we can always adapt to our business requirements. If we don’t have implementation errors, our application will always do exactly what we expect from it.
We cannot guarantee such 100% effectiveness in AI-based applications. Even when our application answers 99% of user queries correctly, we can still find that missing 1% where errors occurred. And manual tests will only show this 1% of errors - without drawing attention to the scale of the problem :)
Tip
Why can’t we guarantee 100% effectiveness?
Under the hood of a language model, like ChatGPT, we don’t have a series of conditional instructions (so-called “ifs”) defining formal logic, but a mathematical function (neural network) containing hundreds of billions of parameters! These numbers are responsible for the probabilities of generating text.
Because of this, neural networks cannot be 100% correct. There will always be some behavior that goes beyond the capabilities of text prediction. Hence, we must treat errors as something we cannot fully eliminate, but we aim to minimize.
The same applies to other ML models - for example, image classifiers.
How to evaluate answer quality?
I’ll start with an abstract framework, because regardless of your application:
- Create a set of test cases and expected response criteria. The criteria should be as clear to interpret as possible, e.g., “answer X contains information about Y”, or “image K was classified as a cat”;
- Measure how your application deals with each case and calculate what % of cases were correct;
- Repeat step two after every change :)
Sounds time-consuming? Not exactly:
- you only need to create the test set once;
- answers can be automatically evaluated using an LLM;
- there are ready-made tools for this!
I will present a real example using a chatbot:
Automatic evaluation using LLMs
Let’s assume we are working on a chatbot for a refrigerator manufacturer - let’s create the 1st test case:
- Question: “How can I contact you?”
- Assessment criteria:
- The answer must contain the address “308 Negra Arroyo Lane, Albuquerque, New Mexico”
- The answer must contain the phone number “+48 123 456 789”
- The answer should be written in a professional tone
When the chatbot generates an answer - e.g., “Yo Mr. White, you can reach us at +48 123 456 789, or drop by in 308 Negra Arroyo Lane, Albuquerque, New Mexico. Cheers!” - we can instruct the LLM with special prompts:
- ✅ Answer YES if the message “Yo buddy…” contains the address “308 Negra Arroyo Lane …”
- ✅ Answer YES if the message “…” contains the phone number “…”
- ❌ Answer YES if the message is written in a professional tone.
The result? The model will determine that the message does not meet all criteria. We will find out what was wrong with it. It will take seconds and cost fractions of a cent :)
Promptfoo - a tool for measuring effectiveness
You probably won’t even have to program such a framework! I will introduce you to a proven open-source tool that might turn out to be sufficient:
Promptfoo is, in my opinion, the best tool for testing prompts and RAG applications. It is free, constantly developed, and tries to be as universal as possible. This post is not sponsored ;)
I encourage you to check the README on Github. Below I include an example configuration that:
- compares 2 prompts for message translation
- compares 2 different LLM providers (gpt-4o and local llama 3)
- for 4 variants (2 different prompts times 2 different providers) performs 2 test cases, of which:
- the first will test translation into French, and check if the output has less than 100 characters
- the second will test translation into German, check output similarity based on embeddings (cosine similarity) and ensure the model does not talk about itself as a language model
prompts:
- file://prompt1.txt
- file://prompt2.txt
providers:
- openai:gpt-4o-mini
- ollama:llama3.1:70b
tests:
- description: 'Test translation to French'
vars:
language: French
input: Hello world
assert:
- type: contains-json
- type: javascript
value: output.length < 100
- description: 'Test translation to German'
vars:
language: German
input: How's it going?
assert:
- type: llm-rubric
value: does not describe self as an AI, model, or chatbot
- type: similar
value: was geht
threshold: 0.6 # cosine similarity
The possibilities are extremely broad, so you can easily adapt the configuration to your needs. You can preview the output in GUI form or read it from the CLI:
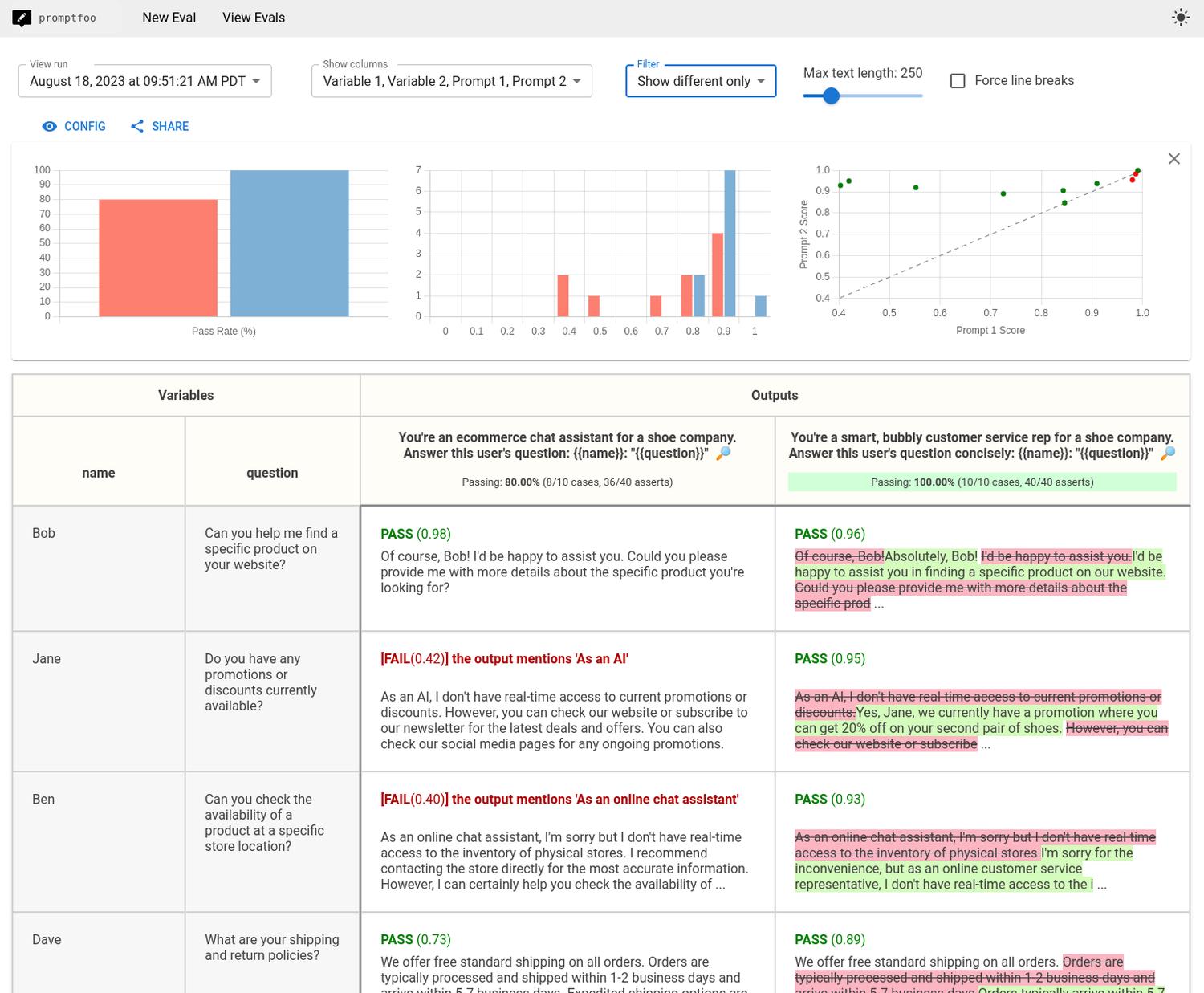
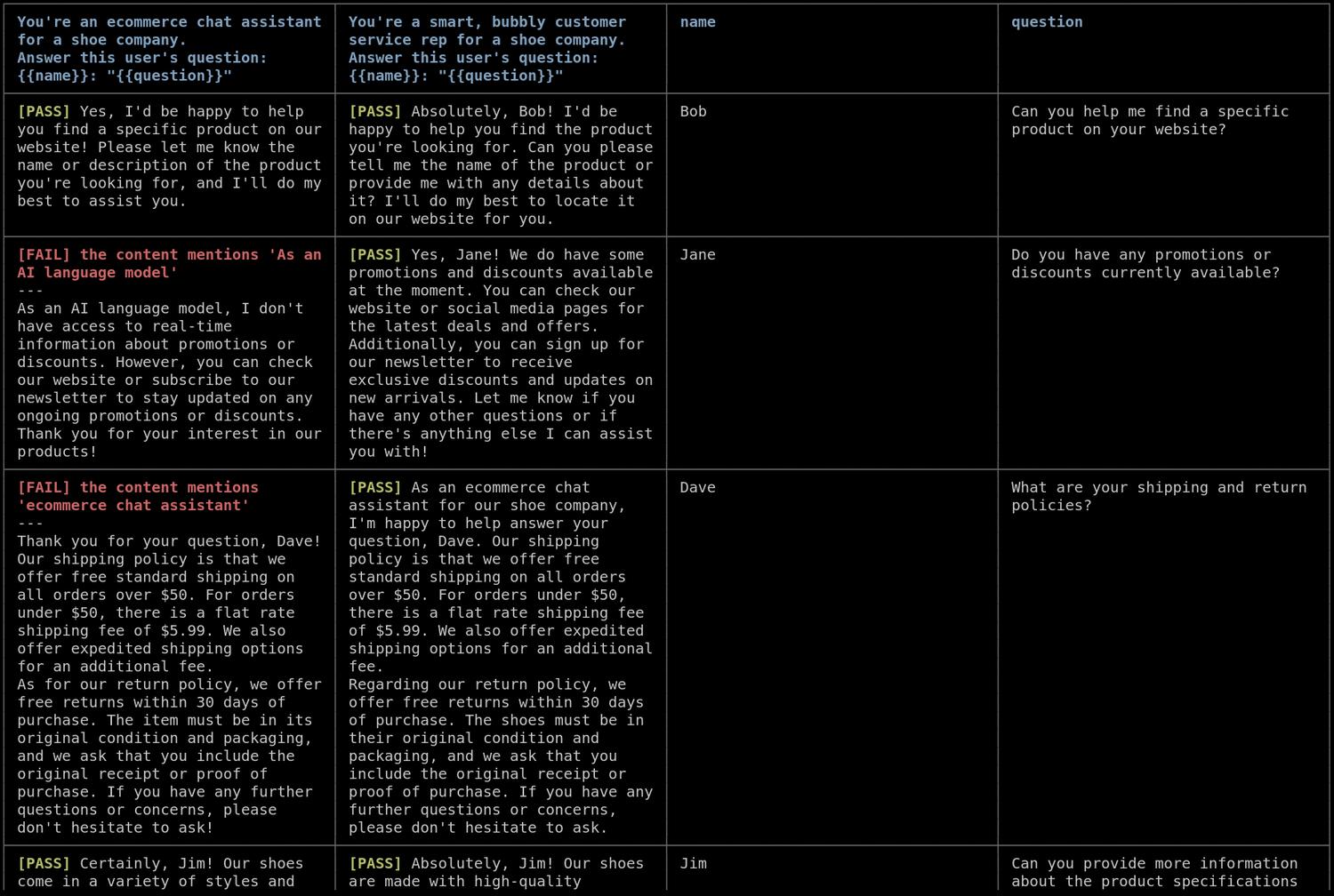
You can control the tool from scripts, e.g., integrate it with CI/CD. Promptfoo allows you to set any application as a provider, meaning you won’t just test the LLM/prompt, but also a custom application.
Creating good tests
Here are a few practical tips for you - because the devil is in the details:
Create a benchmark at the very beginning of work
Start by establishing: what questions should your application answer? What should be their expected answers? What should be paid attention to?
Having a ready list, you can create a prototype of the application. Creating a working MVP will give you a reference point, which you can then gradually improve. You won’t have to rely on subjective feelings, but on a set of effectiveness metrics: 50% accuracy, 60% accuracy, …
Maybe it turns out that for your needs, an early prototype will be good enough? Or conversely - extremely low effectiveness will signal to you that the idea is much harder than you thought.
Don’t create tests for collected data; create tests for the user
It’s easy to fall into the trap of implementing tests based on currently possessed data.
Do you feel a question will be tough enough that the system won’t handle it, e.g., because it requires knowledge from two different system sources, so you don’t add the question to the test set? Or do you browse the database, creating questions directly based on keywords from the original texts?
This is a sign for you to test your system more realistically ;) The user utilizes synonyms, often drops punctuation or capitalization. They might not use terms you know. Maybe they use simpler language, maybe technical terminology, or maybe they use acronyms and abbreviations?
Remember that the goal of tests is the satisfaction of the end user, not artificially boosting a metric.
Ensure diverse test questions
Don’t place only and exclusively hard questions in the tests - including seemingly simple questions will allow you to catch serious regressions that a user of your application would definitely encounter.
For example: if you are creating an application based on RAG, which might not work correctly for various reasons, your test questions should protect against the widest possible range of failures:
- check if the LLM doesn’t hallucinate on questions outside the knowledge scope;
- see if retrieval works correctly for edge cases (synonyms, acronyms, different terminology, incomplete language);
- can an inappropriate response be forced?
- can the LLM be forced to return the system prompt? can it be made to ignore instructions and do something else?
If your system is deployed to production, I recommend monitoring end-user queries (if possible) - nothing constitutes better tests :)
Overfitting
Just as you can overfit an ML model to the training set - so you can overfit an application to a given set of test questions, e.g., for RAG by choosing the wrong embedding model or bending the prompt too much for specific cases.
I recommend ensuring a large size for the test question set. And if you have the resources - create a second set of questions that you will run less frequently to occasionally verify if regression hasn’t occurred :) The methodology is quite similar to training ML models.
Final words and links
I hope this post proved helpful :) If you want to read more articles on this topic, here is a list in the context of RAG:
- Systematically Improving Your RAG, Jason Liu - about RAG improvement methodology
- RAG Evaluation: Don’t let customers tell you first, Pinecone - introduction and explanation of common evaluation metrics
If you noticed any errors, inaccuracies, or would simply like to talk about this topic - feel free to contact me on LinkedIn or via email - contact in the footer :)
Info
If you are experienced in AI, imprecise nomenclature might have caught your eye! When speaking of AI, I meant exclusively ML models, specifically Large Language Models (LLM). Unfortunately, the term AI has been imprecisely adopted in broad awareness and identified with chatbots and LLMs.
Simplified nomenclature allows me to reach a broader group of recipients - maybe a person is reading this who hasn’t yet had the chance to learn the difference between AI/ML/LLM, but after this note, they will google the acronyms :)
You can follow my blog with any
 RSS reader!
RSS reader!
Maciej Kaszkowiak
I try to write about interesting things, such as artificial intelligence, created projects, and travel - see all posts.

Query rewriting - refine user queries
What is query rewriting? Why is it useful whenever you build a chatbot? How to implement it? Read the article!

BM25: keyword search
Improve search in your application! Implement BM25: discover how it works, learn about potential issues, and get practical advice 🚀

Overview of best OCR tools
Overview of tools for effective OCR on PDF files. This article will help you improve the quality of text extracted from your documents! 📄