OCR - ekstrakcja tekstu z PDF
Przegląd narzędzi do efektywnego OCR na plikach PDF. Artykuł pozwoli Ci polepszyć jakość wydobywanego tekstu ze swoich dokumentów! 📄

Info
Aktualizacja z stycznia 2026: poniższy artykuł zdążył się zestarzeć :)
Powstało wiele benchmarków do OCR - nie wymieniam z nazw, bo jeszcze pojawią się lepsze ;) Z aktualnych modelów polecam zainteresować się PaddleOCR-VL.
Czym jest i do czego służy OCR?
OCR (Optical Character Recognition) to proces rozpoznawania tekstu w obrazie. OCR przydaje się, jeśli chcemy przetworzyć tekst z obrazu w dowolny sposób:
- skopiować treść zeskanowanej kartki;
- przetłumaczyć napis ze zdjęcia;
- zeskanować paragon…
OCR okaże się także przydatne, gdy budujemy bazę zeskanowanych dokumentów, które później chcielibyśmy móc przeszukać - na przykład przy Retrieval Augmented Generation :)
Przegląd narzędzi
Tesseract
Tesseract to jedno z najbardziej znanych narzędzi do OCR. W projekcie dostępne jest zarówno narzędzie CLI (tesseract) jak i sam silnik OCR (libtesseract).
Projekt wspiera ponad 100 języków oraz ma wsparcie dla UTF-8, przez co bez problemu poradzi sobie z językiem polskim.
Narzędzia nie można wykorzystać bezpośrednio na plikach PDF. Jako input przyjmuje zdjęcia, przez co w pierwszej kolejności musimy zamienić plik PDF na serię zdjęć.
Tesseract nie radzi sobie między innymi z odręcznym pismem:
It’s possible to train tesseract to recognize handwriting. […] But don’t expect very good results. Academics have typically gotten accuracy results topping out about 90%. Here are a couple references for words and numbers. So if your use case can deal with at least 1/10 errors, this might work for you.
Input powinien być możliwie pozbawiony zanieczyszczeń (które mogą wystąpić przy przykładowo skanowanych dokumentach), aby Tesseract uzyskał optymalne wyniki. Jako output uzyskujemy plain text - Tesseract nie wydobędzie nam struktury dokumentu, czyli chociażby nagłówków.
Tesseract jest objęty licencją Apache 2.0, co umożliwia zarówno zastosowania komercyjne jak i hobbystyczne.
OCRmyPDF
OCRmyPDF jest pełnoprawnym narzędziem do konwertowania PDFów.
Silnikiem OCR jest wcześniej wymieniony Tesseract. OCRmyPDF dodaje nakładkę umożliwiającą przetwarzanie PDFów przed wykonaniem OCR - można ze jego pomocą np. usunąć szum, poprawić obrót stron, usunąć wygląd skanowanego tekstu. Ponadto, narzędzie możemy uruchomić bezpośrednio na plikach PDF.
Zdecydowanie możemy zastosować te narzędzie, jeśli nie zależy nam na ustrukturyzowanym tekście. Program nadaje się świetnie do wydobycia plain textu, a także do nałożenia zeskanowanego tekstu na plik :)
Programem sterujemy z linii komend:
ocrmypdf # it's a scriptable command line program
-l eng+fra # it supports multiple languages
--rotate-pages # it can fix pages that are misrotated
--deskew # it can deskew crooked PDFs!
--title "My PDF" # it can change output metadata
--jobs 4 # it uses multiple cores by default
--output-type pdfa # it produces PDF/A by default
input_scanned.pdf # takes PDF input (or images)
output_searchable.pdf # produces validated PDF output
OCRmyPDF jest objęty licencją MPL 2.0, co możliwia wykorzystywanie komercyjne:
The OCRmyPDF software is licensed under the Mozilla Public License 2.0 (MPL-2.0). This license permits integration of OCRmyPDF with other code, included commercial and closed source, but asks you to publish source-level modifications you make to OCRmyPDF.
Nougat
Nougat jest wyspecjalizowanym narzędziem od Meta do przetwarzania akademickich PDFów, które wspiera tabelki i równania. Output jest w formacie Markdown z równaniami w formacie LaTeX.

Model najlepiej się sprawdza na dokumentach naukowych, podobnych w strukturze do tych z arXiv. Stosowanie Nougat na dokumentach z innej domeny znacząco pogarsza trafność.
Nougat wykorzystuje architekturę Transformerów. Model jest przez to podatny na halucynacje:
Relying on autoregressive forward passes to generate text is slow and prone to hallucination/repetition. From the nougat paper: We observed [repetition] in 1.5% of pages in the test set, but the frequency increases for out-of-domain documents. In my anecdotal testing, repetitions happen on 5%+ of out-of-domain (non-arXiv) pages.
Współczynniki modelu są licencjonowane pod licencją CC-BY-NC, co oznacza, że nie możemy wykorzystać Nougat do rozwiązań komercyjnych.
Marker
Marker jest najbardziej zaawansowanym narzędziem z tego zestawienia do konwertowania plików PDF w format Markdown.
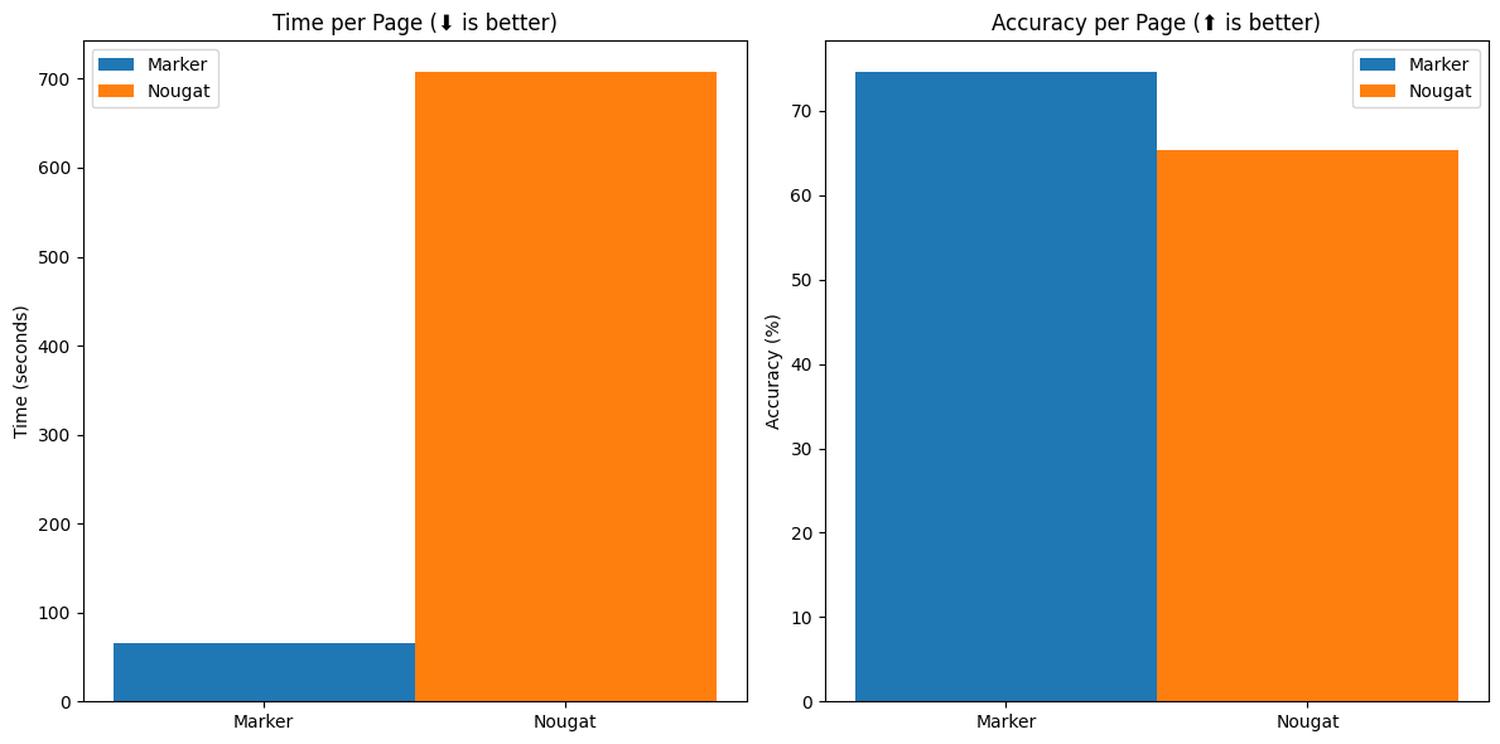
Marker ekstraktuje ustrukturyzowany tekst w formacie Markdown, równań oraz tabel z plików o dowolnej tematyce. Narzędzie jest 10x szybsze od Nougat, zapewnia wyższą trafność oraz ogranicza ryzyko halucynacji wyłącznie do przetworzonych równań w LaTeX.
Marker pod spodem wykorzystuje kilka narzędzi:
Marker is a pipeline of deep learning models:
- Extract text, OCR if necessary (heuristics, tesseract)
- Detect page layout (layout segmenter, column detector)
- Clean and format each block (heuristics, texify)
- Combine blocks and postprocess complete text (heuristics, pdf_postprocessor)
Współczynniki wykorzystywanych modelów są licencjonowane pod licencją CC-BY-NC, co oznacza, że nie możemy wykorzystać Marker do rozwiązań komercyjnych. Sam projekt jest licencjonowany pod licencją copyleft GPL-3.0.
Instalacja Markera na WSL2
Przedstawię jak zainstalować Marker pod systemem WSL2 (Ubuntu 20.04). Instrukcję opieram o dokumentację w repozytorium Marker:
Zacznijmy od zainstalowania Poetry:
curl -sSL https://install.python-poetry.org | python3 -
Upewnijmy się, czy Poetry jest zainstalowane:
$ poetry --version
Poetry (version 1.7.1)
Jeśli tak, pobierzmy repozytorium:
git clone https://github.com/VikParuchuri/marker.git
cd marker
Następnie musimy zainstalować zależności systemowe:
chmod +x scripts/install/tesseract_5_install.sh
scripts/install/tesseract_5_install.sh
chmod +x scripts/install/ghostscript_install.sh
scripts/install/ghostscript_install.sh
cat scripts/install/apt-requirements.txt | xargs sudo apt-get install -y
Kolejnie - skonfigurujmy ścieżkę do Tesseracta:
$ find /usr -name tessdata
/usr/share/tesseract-ocr/5/tessdata
$ nano local.env
TESSDATA_PREFIX=/usr/share/tesseract-ocr/5/tessdata
Następnie aktywujmy środowisko Poetry i zainstalujmy zależności. W moim przypadku instaluję metodą opierającą się wyłącznie o CPU. Jeśli chcecie wykorzystać GPU, zapoznajcie się z dokumentacją.
poetry shell
poetry install
pip3 install torch torchvision torchaudio
Info
W przypadku problemów z paczkami lub poetry, warto usunąć cache oraz ponownie wygenerować lock file.
Uwaga - usunie to wszystkie istniejące środowiska Poetry!
rm -rf ~/.cache/pypoetry/
poetry lock --no-update
Wydobycie treści Markdown z pliku PDF
Po zainstalowaniu Marker, możemy konwertować PDF na MD - na przykładzie konwersji pdf1.pdf > pdf1.md:
poetry shell
python convert_single.py pdf1.pdf pdf1.md --parallel_factor 2
Warto skonfigurować plik local.env, aby uzyskać optymalną jakość wyników:
# DEFAULT_LANG należy ustawić zgodnie z przetwarzanym dokumentem
DEFAULT_LANG=Polish
# Aktywujmy dodatkowy post-processing:
ENABLE_EDITOR_MODEL=true
To wszystko na dzisiaj. Dzięki za przeczytanie artykułu! :)
Możesz śledzić mój blog za pomocą dowolnego
 czytnika RSS!
czytnika RSS!
Maciej Kaszkowiak
Piszę o rzeczach, które uważam za interesujące, m.in. o sztucznej inteligencji, projektach, programowaniu i podróżach - zobacz wszystkie posty.

EnsembleAI 2025, czyli 3 miejsce zdobyte atakiem rakietowym
Poznaj naszą relację z tegorocznego hackathonu EnsembleAI! Inaczej rakiety dolecą do Ciebie ;)

Query rewriting - doprecyzuj zapytania użytkowników
Czym jest query rewriting? Dlaczego przyda Ci się zawsze, gdy tworzysz chatbota? Jak to wdrożyć? Przeczytaj w artykule!

BM25: wyszukiwanie po słowach kluczowych
Ulepsz wyszukiwanie w swojej aplikacji! Wdróż BM25: odkryj jak działa, poznaj problemy i praktyczne porady 🚀